Bigtable: A Distributed Storage System for Structured Data
This is a review of Google's 2006 BigTable paper, presented at OSDI (Operating Systems Design and Implementation). BigTable was a foundational system at Google and has influenced many modern NoSQL databases like Apache HBase, Apache Cassandra, and Google Cloud Bigtable.
If you're curious about how to build systems that scale to handle petabytes of data across thousands of machines, this paper is a masterclass. I've rewritten this review to be accessible to anyone with basic technical knowledge - no distributed systems PhD required!
What is BigTable?
Imagine you need to store and manage massive amounts of data - we're talking about petabytes (thousands of terabytes) of information spread across thousands of computers. That's exactly the problem Google faced in the early 2000s, and BigTable was their solution.
BigTable is a distributed storage system designed to handle structured data at an enormous scale. Think of it as a giant, flexible spreadsheet that can grow to store petabytes of data and handle millions of operations per second. Unlike traditional databases that use SQL and enforce strict relationships between tables, BigTable offers a simpler, more flexible approach.
Google uses BigTable to power many of their core services:
- Web indexing: Storing and searching through billions of web pages
- Google Earth: Managing massive satellite imagery and geographic data
- Google Finance: Handling real-time financial data
What makes BigTable special is its ability to serve these wildly different use cases - from storing tiny URLs to massive satellite images, from running batch processing jobs to serving real-time user requests - all with high performance and reliability.
Design Goals and Philosophy
BigTable was built with four key goals in mind:
- Wide applicability: Work for many different types of applications and data
- Scalability: Handle growth from gigabytes to petabytes seamlessly
- High performance: Serve data quickly, whether from batch jobs or live user requests
- High availability: Keep running even when servers fail (which happens constantly at Google's scale)
Why Not Use a Traditional Database?
You might wonder: why not just use a regular relational database like MySQL or PostgreSQL? The answer is that traditional databases weren't designed for Google's scale. BigTable makes some trade-offs:
What BigTable doesn't have: Complex joins, foreign keys, and SQL queries that traditional databases offer
What BigTable does have: Simple, flexible data storage that lets applications control exactly how and where data is stored
Key Design Principles
- Flexible indexing: Rows and columns can be named using any string you want (like "com.google.www" or "user_12345")
- Data as bytes: BigTable doesn't care what your data looks like - it just stores bytes. Your application decides how to interpret it (as JSON, images, numbers, etc.)
- Control over locality: Smart schema design lets you store related data physically close together, making reads faster
- Memory vs. disk trade-offs: You can tune whether data is served from fast memory or slower disk storage
Data Model: How BigTable Organizes Information
At its core, BigTable can be thought of as a massive, sorted map (like a dictionary or hash table). Here's the formal definition:
(row:string, column:string, time:int64) → string
This means: give me a row name, a column name, and a timestamp, and I'll give you back the data stored at that location.
Let's break down each dimension with a real example - imagine storing web pages:
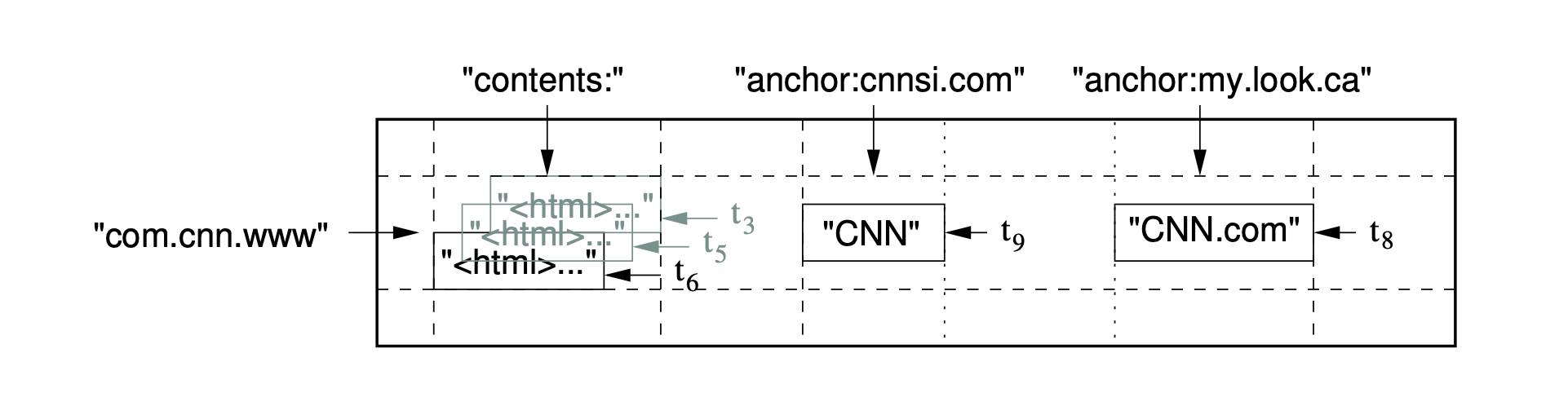
Rows: The Primary Index
Think of rows as the main way to organize your data. Each row has a unique key (like "com.cnn.www" for CNN's website).
Key features:
- Atomic operations: All reads/writes to a single row happen completely or not at all - no half-finished operations. This makes your code simpler because you don't have to worry about partial updates.
- Sorted storage: BigTable keeps rows sorted alphabetically (lexicographically). This means "com.cnn.www" and "com.cnn.www/sports" will be stored near each other.
- Tablets for distribution: BigTable automatically splits tables into chunks called tablets. Think of a tablet as a subset of rows (like rows A-M on one server, N-Z on another). This allows BigTable to:
- Spread data across multiple machines
- Balance load by moving tablets between servers
- Make range scans efficient (reading "com.cnn.*" only touches servers with those rows)
Column Families: Grouping Related Data
Columns are organized into groups called column families. This is a crucial concept for performance.
Example: When storing web pages, you might have:
contents:family for the HTML contentanchor:family for all links pointing to this pagemetadata:family for information about the page
Why this matters:
- Compression: Data in the same family is compressed together, saving massive amounts of disk space
- Access control: You can set permissions per family (e.g., only some users can read
metadata:) - Performance tuning: You can configure each family differently (memory vs. disk, compression settings, etc.)
Design guideline: Keep the number of column families small (hundreds at most) because they rarely change. However, you can have unlimited individual columns within a family (like anchor:cnnsi.com, anchor:my.look.ca, etc.).
Timestamps: Time-Travel for Your Data
Every cell in BigTable can store multiple versions of the same data, each with a different timestamp. This is incredibly powerful for many use cases.
Example: You could store multiple versions of a web page as it changes over time.
Automatic cleanup: To prevent storing infinite versions, BigTable offers two garbage collection options:
- Keep last N versions: "Only keep the 3 most recent versions"
- Keep recent versions: "Only keep versions from the last 7 days"
This time-versioning is automatic and configurable per column family.
API: How Applications Talk to BigTable
BigTable provides a straightforward API for applications to interact with data:
Basic Operations
Table and schema management:
- Create and delete tables and column families
- Modify metadata like access control permissions
- Change configuration settings
Data operations:
- Write or delete values
- Look up values from individual rows
- Scan through a range of rows (like finding all pages from "com.cnn.*")
Advanced Features
Single-row transactions: You can perform atomic read-modify-write operations on a single row. For example, "read the current counter value, add 1, and write it back" - all guaranteed to happen as one indivisible operation, even if multiple clients try to update simultaneously.
Integer counters: BigTable has built-in support for counter columns, making it easy to track things like page views or votes without worrying about race conditions.
Server-side processing: You can run custom scripts directly on BigTable servers using a Google-developed language called Sawzall. This lets you process data where it lives, avoiding expensive data transfers.
MapReduce integration: BigTable works seamlessly with MapReduce (Google's distributed data processing framework). You can read data from BigTable, process it with MapReduce, and write results back to BigTable - perfect for large-scale analytics and batch processing.
Building Blocks: The Foundation of BigTable
BigTable doesn't work alone - it's built on top of several other distributed systems that Google developed. Think of these as the infrastructure layers that BigTable relies on:
Google File System (GFS)
BigTable stores all its data files and logs in GFS, Google's distributed file system. GFS handles the complexity of storing massive files across thousands of machines, dealing with disk failures, and providing redundancy. BigTable doesn't worry about which physical disk holds what data - GFS manages all of that.
SSTable: The Storage Format
SSTable (Sorted String Table) is the file format BigTable uses to store data on disk. Think of it as a simple but powerful data structure:
- Sorted: Keys are stored in alphabetical order
- Immutable: Once written, an SSTable never changes (this makes many optimizations possible)
- Persistent map: Maps keys to values, both stored as byte strings
- Indexed: Each SSTable includes an index (stored at the end) that's loaded into memory, making it fast to find specific keys without scanning the entire file
Chubby: The Distributed Lock Service
Chubby is Google's distributed lock service - think of it as a highly reliable coordinator for distributed systems. It solves a critical problem: how do you coordinate thousands of machines and ensure they agree on important decisions?
How Chubby works:
- Uses the Paxos algorithm (a consensus protocol) to stay consistent even when some machines fail
- Maintains sessions with clients using leases (time-limited permissions)
- If a client can't renew its lease before it expires, it loses all its locks and handles
- Provides callbacks to notify clients of changes or session problems
Why BigTable needs Chubby:
- Master election: Ensures only one master server is active at any time (prevents split-brain scenarios)
- Bootstrap location: Stores the starting point for finding BigTable data
- Tablet server discovery: Tracks which tablet servers are alive and working
- Schema storage: Keeps the master copy of table definitions and column families
- Access control: Stores who can access what data
Think of Chubby as BigTable's control plane - it doesn't handle data directly, but it coordinates all the servers and maintains critical metadata.
Cluster Management System
BigTable also depends on Google's cluster management infrastructure for:
- Scheduling jobs across the cluster
- Managing resources (CPU, memory, disk) on shared machines
- Detecting and recovering from machine failures
- Monitoring the health of all servers
Implementation: How BigTable Actually Works
BigTable's architecture consists of three main components working together:
The Three Components
- Client library: Linked into every application that uses BigTable
- Master server: One master coordinates everything (with Chubby ensuring only one is active)
- Tablet servers: Many servers that actually store and serve data
The Master Server: The Coordinator
The master is like an orchestra conductor - it doesn't play instruments itself, but coordinates everyone else:
Responsibilities:
- Tablet assignment: Decides which tablet server should handle which tablets
- Server monitoring: Detects when tablet servers join or fail
- Load balancing: Moves tablets between servers to distribute work evenly
- Garbage collection: Cleans up old files in GFS that are no longer needed
- Schema management: Handles table and column family creation/deletion
Master startup process:
- Grabs a unique master lock in Chubby (ensures no other master is running)
- Scans Chubby's servers directory to find live tablet servers
- Talks to each tablet server to learn which tablets they're serving
- Scans the
METADATAtable to find all tablets, and assigns any unassigned ones
Tablet Servers: The Workers
Tablet servers do the actual data work:
Responsibilities:
- Handle read and write requests for their assigned tablets
- Split tablets that grow too large (keeping them around 100-200 MB)
- Manage the in-memory and on-disk data structures
Tablet server registration: When a tablet server starts, it creates a uniquely-named file in Chubby and acquires an exclusive lock on it. This is how the master knows the server is alive. If the server crashes or becomes unreachable, it loses the lock, and the master knows to reassign its tablets.
How Data is Organized
Tables → Tablets → SSTables
- A table is divided into tablets (chunks of rows)
- Each tablet starts at 100-200 MB and contains a contiguous range of rows
- Tables start with just one tablet and automatically split as they grow
- A three-level hierarchy (similar to a B+ tree) stores tablet location information, making it fast to find which server has your data
The Write Path: From Memory to Disk
Understanding how writes work is key to understanding BigTable:
- Writes go to memory first: New data is written to an in-memory structure called the memtable (think of it as a sorted buffer)
- Writes are logged: Simultaneously, writes are recorded in a commit log in GFS for durability
- Memtable fills up: When the memtable reaches a threshold size, it gets "frozen"
- Conversion to SSTable: A new memtable is created for new writes, and the frozen memtable is converted to an SSTable and written to GFS
- Data becomes persistent: Now the data is safely on disk in immutable SSTable files
This design gives you fast writes (memory) with durability (commit log) and efficient storage (immutable SSTables).
Performance Optimizations: Making BigTable Fast
The basic BigTable design is solid, but Google added several clever optimizations to make it blazingly fast. Here are the key refinements:
Locality Groups: Better Organization
The problem: Different column families are often accessed in different patterns. For example, you might frequently read page content but rarely read metadata.
The solution: Group column families that are accessed together into locality groups. Each locality group gets its own set of SSTables.
The benefit: When you read the content, you don't have to load metadata from disk, making reads much faster.
Compression: Saving Space
BigTable allows per-locality-group compression, and the results are impressive. Many clients use a two-pass compression scheme:
- First pass: Bentley and McIlroy's scheme compresses long repeated strings across a large window (great for web pages with repeated boilerplate)
- Second pass: A fast algorithm looks for repetitions in small 16 KB windows
Performance: Encoding at 100-200 MB/s, decoding at 400-1000 MB/s on typical hardware. The compression is so fast that it's often worth it just to reduce disk I/O.
Caching: Speed Up Reads
BigTable uses two levels of caching:
- Scan Cache (high-level): Caches key-value pairs returned by the SSTable interface. Great when you repeatedly read the same data.
- Block Cache (low-level): Caches raw SSTable blocks read from GFS. Helps when you read different data from the same locality (spatial locality).
Using both caches together dramatically improves read performance.
Bloom Filters: Avoid Unnecessary Disk Reads
The problem: You need to read data, but you don't know which SSTables contain it. Checking every SSTable is slow.
The solution: Each SSTable has a Bloom filter - a compact probabilistic data structure that can answer "this SSTable definitely does NOT contain this row/column" with certainty, or "it might contain it" (requiring a disk check).
The benefit: A tiny amount of memory (storing Bloom filters) eliminates most unnecessary disk seeks. For some applications, this is a huge win.
Smart Commit Log Design
The challenge: Using one commit log per tablet server (instead of one per tablet) provides better write performance, but makes recovery more complex when a server fails.
The trade-off: BigTable chose the single-log approach and handles the recovery complexity, prioritizing normal-case performance.
Fast Tablet Recovery
When a tablet needs to be moved to a new server:
- The old server does a quick minor compaction (flushes memtable to SSTable)
- Then does another minor compaction to catch any writes that came in during step 1
- This minimizes recovery time by reducing the amount of commit log the new server needs to replay
Exploiting Immutability
Key insight: SSTables never change after they're written. This enables several optimizations:
For memtables: Use copy-on-write for each row, allowing reads and writes to proceed in parallel without blocking each other.
For tablet splitting: When a tablet gets too big and needs to split:
- OLD way: Generate new SSTables for each child tablet (slow)
- BIGTABLE way: Child tablets just share pointers to the parent's SSTables (instant)
The immutability of SSTables makes this safe - since files never change, multiple tablets can safely reference the same files.
Real Applications: BigTable in Production
To understand BigTable's impact, let's look at how it was actually being used at Google. As of August 2006 (when the paper was published), there were 388 non-test BigTable clusters running across Google's infrastructure, with a combined total of about 24,500 tablet servers. That's massive scale!
Google Analytics: Tracking Billions of Clicks
Google Analytics processes enormous amounts of web traffic data. Here's how they used BigTable:
Raw click table (~200 TB):
- One row per user session on a website
- Row key design: Combines website name and session creation time (e.g., "example.com#2006-08-15T14:30:00")
- Why this design? Sessions from the same website are stored together and sorted chronologically - perfect for queries like "show me all sessions for example.com on August 15th"
- Compression wins: The table compresses to just 14% of its original size (from 200 TB to ~28 TB) thanks to repetitive structure
Summary table (~20 TB):
- Contains pre-aggregated statistics for each website (page views, unique visitors, bounce rates, etc.)
- Generated by MapReduce jobs that periodically process the raw click table
- Much smaller because it's aggregated data rather than individual clicks
Google Earth: Managing Geographic Data
Google Earth stores massive amounts of satellite imagery and geographic information:
Imagery table:
- One row per geographic segment (think of segments as tiles of the Earth's surface)
- Row key design: Named to ensure adjacent geographic segments are stored physically close together (e.g., using geohash or similar encoding)
- Why this matters? When you pan around Google Earth, nearby tiles are likely on the same tablet server, making loads fast
- Processing pipeline: Heavy use of MapReduce jobs over BigTable to process and transform raw imagery
- Performance: Processes over 1 MB/sec of data per tablet server during MapReduce operations
Personalized Search: User Profiles
Google's Personalized Search used BigTable to improve search results based on user history:
User profile generation:
- MapReduce jobs process user behavior data stored in BigTable
- Generate personalized profiles (search history, clicked results, preferences)
- These profiles are then used in real-time to customize search results for each user
Why BigTable? Needs to handle hundreds of millions of user profiles, with frequent updates and fast read access during searches.
Lessons Learned: Wisdom from Building at Scale
After building and operating BigTable at massive scale, the Google team shared some valuable lessons that apply to any large distributed system:
Expect Every Type of Failure
The reality: Large distributed systems face way more failure modes than you'd expect from textbooks. It's not just network partitions or servers crashing cleanly.
Real-world failures include:
- Memory corruption
- Network congestion (not failure, just slowness)
- Disk errors that corrupt data silently
- Clock skew between machines
- Resource exhaustion (running out of file descriptors, threads, etc.)
- Bugs that only appear at scale
The lesson: Design defensively and assume anything that can fail, will fail - often in surprising ways.
Don't Build Features You Don't Need Yet
The temptation: When building infrastructure, it's easy to add features "just in case" they're needed later.
The reality: Wait until you understand actual use cases before adding complexity. Many anticipated features turn out to be unnecessary or need to work differently than originally imagined.
The benefit: Keeps the system simpler and more maintainable. You can add features later when you understand the real requirements.
Simple Designs Win
This was called out as the most important lesson. BigTable comprises about 100,000 lines of non-test code - that's a substantial system. Here's why simplicity mattered:
Why simplicity is critical:
- Maintenance: Simple code is easier to modify when requirements change
- Debugging: When things go wrong (and they will at scale), simple designs make problems easier to diagnose
- Evolution: Code evolves in unexpected ways over time; starting simple makes evolution less painful
- Team scaling: New engineers can understand and contribute to simple systems faster
The trade-off: Simple doesn't mean crude or inefficient. BigTable's design is elegant - it does a lot with relatively few concepts (rows, columns, timestamps, tablets, SSTables). This conceptual simplicity makes it powerful while remaining understandable.
Quote from the paper: "Code and design clarity are of immense help in code maintenance and debugging."
This is perhaps the most transferable lesson - whether you're building a small web app or a planet-scale distributed system, favoring simplicity and clarity over cleverness pays dividends.
Further Reading
Want to dive deeper? Here are the resources:
- Original paper: The complete BigTable paper (18 pages)
- Annotated copy: My personal annotations and notes
Modern Descendants
If you want to use BigTable-inspired systems today:
- Google Cloud Bigtable: Google's managed service (the real deal)
- Apache HBase: Open-source BigTable implementation on Hadoop
- Apache Cassandra: Combines BigTable's data model with Amazon Dynamo's distribution design
- ScyllaDB: C++ rewrite of Cassandra focused on performance
Each of these has evolved beyond the original BigTable design, but you can see its influence in their architecture and data models.
About This Series
This is #6 in my series reviewing foundational papers in Computer Science. The goal is to make these important papers accessible to working engineers who want to deepen their understanding of distributed systems, databases, and infrastructure.
If you found this helpful, check out my reviews of related papers:
- MapReduce: Google's distributed processing framework
- Google File System: The storage layer beneath BigTable