Large-scale cluster management at Google with Borg
What is Borg?
Imagine you need to run thousands of different applications across tens of thousands of computers simultaneously. How do you decide which program runs on which machine? How do you handle failures? How do you make sure resources aren't wasted? This is the problem Google's Borg system solves.
Borg is Google's internal cluster management system - essentially an operating system for data centers. Just as your computer's OS manages programs running on your laptop, Borg manages hundreds of thousands of jobs running across massive clusters of machines. It's been running Google's infrastructure for over a decade, powering everything from Gmail to Google Search.
The key innovations of Borg include:
- Efficient resource usage: Borg achieves high utilization by packing tasks intelligently, sharing machines between different applications, and even overcommitting resources (similar to how airlines overbook seats)
- High availability: Built-in features minimize downtime and recovery time when things fail (and at this scale, something is always failing)
- Developer-friendly: Developers don't need to worry about which specific machines run their code - they just describe what they need, and Borg handles the rest
This paper is particularly important because many of Borg's lessons directly influenced Kubernetes, the now-ubiquitous open-source container orchestration system.
Why Borg Matters
At Google's scale, managing infrastructure manually is impossible. Borg handles the complete lifecycle of applications: it decides whether to accept a new job, schedules it on appropriate machines, starts it, monitors it, and restarts it if it fails.
The system provides three critical benefits:
- Abstraction: Developers don't need to understand the complexities of resource management or failure handling. They simply define what their application needs, and Borg takes care of the rest.
- Reliability: Borg achieves very high reliability and availability, which is essential for services that billions of people depend on every day.
- Scale: It enables operators to efficiently manage workloads across tens of thousands of machines - something that would be impossible to do manually.
To understand Borg's importance, consider that virtually all of Google's major infrastructure runs on it: the distributed file systems (GFS and CFS), the database system (Bigtable), and the storage system (Megastore) all depend on Borg to run.
High-Level Architecture
Let's start with the basic building blocks of Borg:
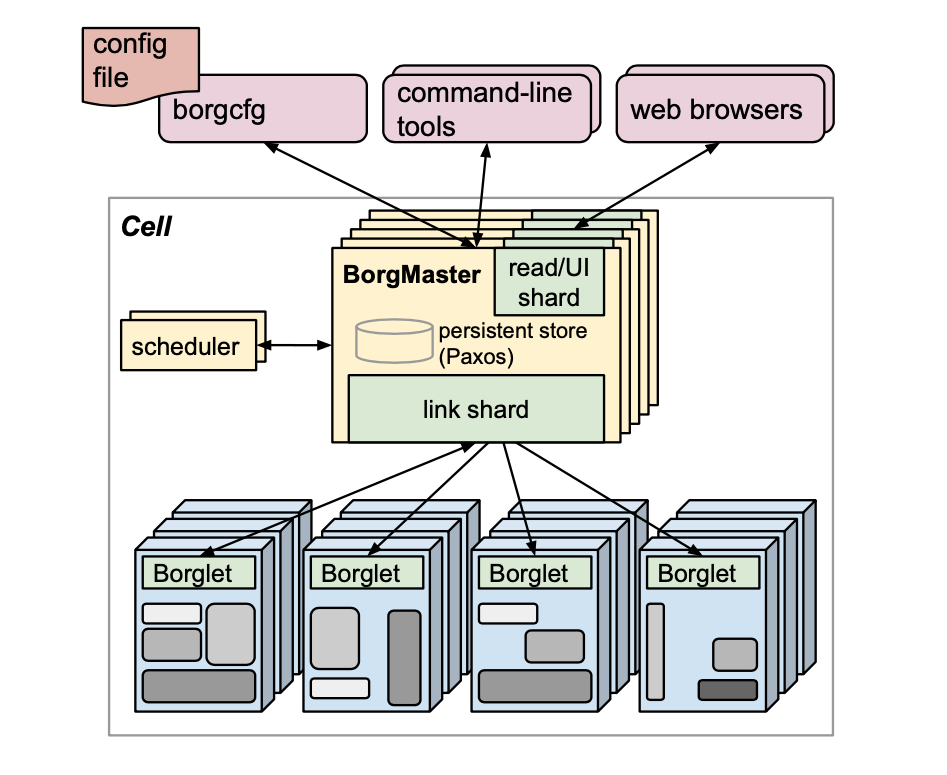
Jobs and Tasks: When you want to run something on Borg, you submit a job. A job consists of one or more tasks - each task is an instance of the same program. For example, if you need to run a web server with 100 replicas for redundancy, you'd submit one job with 100 tasks. Each job runs in one Borg cell, which is a set of machines managed as a single unit (typically around 10,000 machines).
Two Types of Workloads: Borg handles fundamentally different types of work:
- Long-running services (called "prod" jobs): These are user-facing services like Gmail or Search that should never go down. They run continuously and need high availability.
- Batch jobs (called "non-prod"): These are background computations that might take seconds to days to complete, like processing analytics data or indexing web pages. They're more tolerant of interruptions.
Physical Organization: The infrastructure is organized hierarchically:
- A cluster is all the machines in a single datacenter building
- A site is a collection of buildings
- Each cluster typically hosts one large cell (plus some smaller test cells)
- The median cell contains about 10,000 machines, and the system is designed with no single point of failure
Application Packaging: Borg applications are statically linked (meaning all dependencies are bundled with the application) to avoid runtime environment issues. Applications are packaged as bundles of binaries and data files, and Borg handles distributing these packages to the right machines.
Configuration Language: Developers describe their jobs using BCL (Borg Configuration Language), a declarative language that specifies what resources are needed rather than how to obtain them. This is similar to how you might describe a desired state in YAML for modern systems like Kubernetes.
Key Concepts
Allocs (Allocations): Think of an alloc as reserving a parking spot at a parking garage. Once you reserve it, that spot is yours whether you park a car there or not. Similarly, an alloc is a reserved set of resources on a machine where one or more tasks can run. The resources stay reserved even if they're not being used. This is useful for grouping related tasks together (like a web server and its logging helper).
Priority System: Not all work is equally important. Borg uses a priority system with four bands, from highest to lowest:
- Monitoring: Critical infrastructure monitoring (highest priority)
- Production: User-facing services like Gmail
- Batch: Background processing work
- Best effort: Testing and experimental workloads (lowest priority, essentially free)
When resources are scarce, higher-priority tasks can preempt (evict) lower-priority ones. However, production tasks cannot preempt each other to prevent cascading failures. There's also a clever detail: MapReduce master tasks (which coordinate workers) run at slightly higher priority than their workers, ensuring the coordinator stays alive even when resources are tight.
Quota System: To prevent any single team from monopolizing resources, Borg uses quotas. A quota is like a resource budget that specifies how much CPU, RAM, disk, etc., a team can use at a given priority level over a period (typically months).
Quota checking happens during admission control (when Borg decides whether to accept a job) rather than during scheduling. Interestingly, teams often "overbuy" quota to protect against future growth. Borg handles this by overselling quota at lower priorities - everyone effectively has infinite quota at priority zero (best effort), though actually using it depends on available resources.
This quota system reduces the need for complex fairness algorithms like Dominant Resource Fairness (DRF), and Borg also includes a capability system that grants special privileges to certain users.
Naming and Monitoring
Borg Name Service (BNS): Every task gets a unique, human-readable name that includes the cell name, job name, and task number. For example, the 50th task in job "jfoo" owned by user "ubar" in cell "cc" would be:
50.jfoo.ubar.cc.borg.google.com
This name is stored in Chubby (Google's distributed lock service), which allows other services to find the task's actual hostname and port. This naming system provides a stable identifier even as tasks move between machines.
Health Checking: Almost every Borg task includes a built-in HTTP server that exposes a health-check endpoint. Borg continuously polls this endpoint and automatically restarts tasks that don't respond or return error codes. This ensures failing tasks are quickly detected and replaced.
User Interface and Monitoring:
- Sigma provides a web-based UI for monitoring jobs and tasks
- Logs are automatically rotated to prevent disk space issues and preserved after tasks exit to help with debugging
- If a job isn't running, Borg provides a "why pending?" annotation to help diagnose the issue
- All job submissions, task events, and detailed resource usage are recorded in Infrastore (a scalable data store) and can be queried using Dremel (Google's interactive SQL-like query system)
System Components
A Borg cell has three main components working together:
1. Borgmaster (The Brain): This is the centralized controller that manages the entire cell. It actually consists of two separate processes:
- Main Borgmaster process: Handles all API requests (creating jobs, querying status, etc.), manages the state of all objects (machines, tasks, allocations), and communicates with all the Borglets. Think of it as the conductor of an orchestra.
- Scheduler: Separated into its own process to enable parallel operation (more on scheduling below)
For high availability, the Borgmaster is replicated five times using a consensus protocol. When the primary fails, electing a new master and failing over typically takes only about 10 seconds. The Borgmaster's state is periodically saved as a checkpoint for recovery purposes.
An interesting testing tool called Fauxmaster is a high-fidelity Borgmaster simulator used for capacity planning and validation, with stubbed-out interfaces to the Borglets.
2. The Scheduler (The Matchmaker): When you submit a job, the Borgmaster persists it (using Paxos for consistency) and adds its tasks to a pending queue. The scheduler then asynchronously processes this queue, working on individual tasks in round-robin fashion within each priority level.
The scheduling algorithm works in two phases:
-
Feasibility checking: Find machines that meet the task's requirements and have enough "available" resources. Note that "available" includes resources currently used by lower-priority tasks that could be evicted if needed.
-
Scoring: Among feasible machines, pick the best one based on criteria like:
- Minimizing the number and priority of tasks that need to be preempted
- Preferring machines that already have the task's packages cached (faster startup)
- Spreading tasks across power and failure domains (for resilience)
- Packing quality - mixing high and low priority tasks on the same machine to maximize utilization
Performance Note: Task startup takes a median of 25 seconds, with 80% of that time spent on package installation. The main bottleneck is contention for local disk I/O. To optimize this, Borg uses package caching (since packages are immutable) and distributes packages using tree and torrent-like protocols for parallel delivery.
3. Borglet (The Local Agent): Each machine in the cell runs a Borglet - think of it as the Borgmaster's local representative. The Borglet's responsibilities include:
- Starting and stopping tasks
- Restarting failed tasks
- Managing local resources by adjusting OS kernel settings
- Rotating debug logs
- Reporting machine state to the Borgmaster and monitoring systems
Communication Pattern: Rather than Borglets pushing updates to the Borgmaster (which could overwhelm it), the Borgmaster polls each Borglet every few seconds. This pull-based model gives the Borgmaster control over communication rate, avoids flow control complexity, and prevents "recovery storms" (where many agents try to reconnect simultaneously after a failure).
Scalability and Resilience:
- To scale, each Borgmaster replica runs stateless "link shards" to handle communication with subsets of Borglets
- For resilience, Borglets always report their full state (not just changes), making recovery straightforward
- Critically, Borglets continue operating normally even if they lose contact with the Borgmaster, so running tasks stay up even during control plane failures
Scalability Techniques
The numbers are impressive: a single Borgmaster manages thousands of machines with arrival rates exceeding 10,000 tasks per minute. A busy Borgmaster uses 10-14 CPU cores and up to 50 GiB of RAM.
To achieve this scale, Borg employs several key techniques:
Architectural Separation:
- Splitting the scheduler into a separate process allows it to run in parallel with other Borgmaster functions
- Separate threads handle Borglet communication and read-only API requests, improving response times
Scheduler Optimizations: The scheduler uses three critical techniques that make the difference between scheduling completing in a few hundred seconds versus taking over 3 days:
- Score caching: Reuse scoring calculations when machine properties haven't changed
- Equivalence classes: Group tasks with identical requirements together. The scheduler only evaluates feasibility and scoring for one representative task per group, then applies the results to all tasks in that class.
- Relaxed randomization: Instead of exhaustively evaluating all machines, examine them in random order until finding "enough" feasible candidates, then pick the best from that subset. This trades a small amount of optimality for massive performance gains.
These optimizations are crucial - disabling them means a full scheduling pass doesn't finish even after 3+ days!
Availability
Borg achieves an impressive 99.99% availability (less than an hour of downtime per year) through multiple defensive strategies:
- Replication: The Borgmaster is replicated five times, so machine failures don't take down the control plane
- Admission control: Prevents overload by rejecting work that would exceed capacity
- Simple deployment: Uses basic, low-level tools to minimize dependencies that could fail
- Cell independence: Each cell operates independently, so operator errors or failures don't cascade across the entire system
Interestingly, the decision to keep cells at around 10,000 machines isn't driven by scalability limits - it's a deliberate choice to maintain fault isolation and minimize blast radius.
Utilization: Making Every Machine Count
At Google's scale, even small improvements in utilization translate to millions of dollars in savings. To rigorously evaluate scheduling policies, the paper introduces a clever metric called cell compaction.
Cell Compaction: Think of it like packing a suitcase - how efficiently can you fit everything in? Given a workload, they progressively remove machines from a cell until the workload no longer fits, repeatedly re-packing from scratch to avoid getting stuck in suboptimal configurations. This metric directly translates to cost: better policies need fewer machines for the same workload.
The results reveal several surprising insights:
1. Mixing Workloads is Essential: Segregating production and batch jobs would require 20-30% more machines. By sharing machines between different types of work, Borg achieves much better utilization.
2. The Benefits Outweigh the Costs: While sharing machines does introduce some CPU contention and slowdown, this is vastly outweighed by the reduction in required machines. The benefits apply to all resources - CPU, memory, and disk.
3. Flexible Resource Allocation Matters: Borg users specify resources in fine-grained units (milli-cores for CPU, bytes for memory and disk). Many cloud providers offer fixed-size VMs or containers, but Borg's analysis shows this would require 30-50% more resources for their workloads. One size definitely doesn't fit all.
4. Resource Reclamation: This is one of Borg's cleverest tricks. Jobs specify a resource limit (maximum they could use), but Borg continuously estimates actual usage and reclaims the unused portion for lower-priority work like batch jobs. The Borgmaster updates these estimates every few seconds based on fine-grained usage data from Borglets. The result? About 20% of workload runs in reclaimed resources in a typical cell - that's massive savings!
Isolation: Playing Nice Together
Here's a striking statistic: 50% of machines run 9 or more tasks simultaneously. Sharing machines this aggressively requires sophisticated isolation to prevent tasks from interfering with each other.
Security Isolation: Borg uses Linux chroot jails as the primary mechanism to isolate tasks from each other, preventing unauthorized access to other tasks' files and resources.
Performance Isolation: This is more nuanced. All Borg tasks run inside Linux cgroup-based resource containers, with the Borglet manipulating container settings. This gives fine-grained control since the OS kernel enforces the limits.
Borg uses two key classification systems:
-
Application Classes (appclass): Tasks are classified by their latency sensitivity. High-priority, latency-sensitive tasks (like serving user requests) get premium treatment and can temporarily starve batch tasks for several seconds when needed. This ensures user-facing services remain responsive even under load.
-
Resource Compressibility: Resources are divided into:
- Compressible resources (like CPU): Can be throttled without killing the task
- Non-compressible resources (like memory): Once allocated, can't be taken away without terminating the task
CPU Scheduling Challenges: The standard Linux CPU scheduler (CFS - Completely Fair Scheduler) needed substantial tuning to achieve both low latency for production tasks and high utilization overall. One helpful factor: many Google applications use a thread-per-request model, which naturally mitigates persistent load imbalances by distributing work across many threads.
Borg's Place in the Ecosystem
It's helpful to understand how Borg relates to other cluster management systems:
Apache Mesos (developed concurrently at UC Berkeley): Takes a different architectural approach by splitting resource management between a central manager (similar to Borgmaster without the scheduler) and multiple "frameworks" like Hadoop and Spark. Mesos uses an "offer-based" mechanism where the central manager offers resources to frameworks, which then decide whether to accept them.
Google's Omega (Borg's successor): An experimental system that explored a more flexible architecture. Rather than Borg's monolithic scheduler, Omega supports multiple parallel, specialized schedulers using optimistic concurrency control (try to schedule, and if there's a conflict, retry). This design better supports diverse workloads with different scheduling needs. However, Borg's "one size fits all" approach proved sufficient, and scalability hasn't been a problem, so Omega remained experimental.
Kubernetes (the open-source successor): Many of Borg's core ideas live on in Kubernetes, which Google released as open source. Kubernetes places applications in Docker containers across multiple machines and runs on both bare metal (like Borg) and various cloud providers. The lessons from Borg directly shaped Kubernetes's design.
Other Systems: The broader ecosystem includes YARN (Hadoop's resource manager), Facebook's Tupperware, Twitter's Aurora, Microsoft's Autopilot and Apollo, and Alibaba's Fuxi - all tackling similar problems at massive scale.
Lessons Learned: From Borg to Kubernetes
One of the most valuable sections of the paper discusses what worked, what didn't, and how these lessons influenced Kubernetes. This is remarkably candid self-critique from Google.
What Didn't Work Well
1. Jobs as the Only Grouping Mechanism: In Borg, "jobs" are the fundamental way to group tasks. This proved too rigid. Kubernetes learned from this by using labels - arbitrary key/value pairs you can attach to any object. Need to select all tasks for a particular service version? Use a label query. This is far more flexible than Borg's hierarchical job structure.
2. One IP Per Machine: This might seem minor, but it caused significant complexity. Borg had to:
- Treat ports as schedulable resources
- Require tasks to pre-declare port needs
- Enforce port isolation at the Borglet level
- Handle ports throughout the naming and RPC systems
Kubernetes solved this elegantly: every pod and service gets its own IP address. Developers can freely choose ports without coordination, and the infrastructure complexity of port management disappears.
3. Complexity for Power Users vs. Casual Users: The BCL configuration language has about 230 parameters. While this gives power users fine-grained control, it creates a steep learning curve for casual users and makes the system harder to evolve (since people depend on all those parameters). Kubernetes learned to favor simplicity and provide escape hatches for advanced use cases rather than exposing everything by default.
What Worked Well
1. Allocs Are Useful: The alloc concept (grouping related tasks together) proved valuable because it allows helper services to be developed by separate teams yet deployed together. For example, a logging sidecar can be developed independently but run alongside the main application. Kubernetes adopted this as the pod concept - a resource envelope for one or more containers that are always co-located on the same machine and can share resources.
2. Cluster Management Is More Than Task Management: A profound insight: you need more than just "run this program on a machine." Kubernetes expanded on this with the service abstraction: a service has a stable name and a dynamic set of pods defined by a label selector. Applications connect using the service name, and Kubernetes automatically load-balances requests and tracks pods as they move due to failures or rescheduling. This makes building distributed systems much simpler.
3. Introspection Is Vital: Making system state visible and queryable proved essential for debugging and operations, even though it makes deprecating features harder (since users come to rely on inspecting internal details). The transparency is worth the cost - there's no realistic alternative when operating at scale.
4. The Master Is a Kernel, Not a Monolith: Perhaps the most important architectural lesson. The Borgmaster sits at the heart of an ecosystem of cooperating services: the UI (Sigma), admission control, autoscaling, task re-packing, cron-like job submission, workflow management, and more.
Kubernetes takes this philosophy even further. Its API server is responsible only for processing requests and manipulating state objects. All cluster management logic lives in small, composable microservices that are clients of the API server:
- The replication controller maintains desired replica counts
- The node controller manages machine lifecycle
- Other controllers handle services, deployments, etc.
This microservices architecture makes Kubernetes more extensible and easier to evolve than Borg's more monolithic design.
Key Takeaways
If you remember nothing else from this paper, remember these points:
-
Scale requires abstraction: At Google's scale, developers can't worry about individual machines. Borg's declarative interface (specify what you need, not how to get it) is essential.
-
Mixing workloads is a superpower: Running production and batch jobs on the same machines, plus resource reclamation, achieves 20-50% better utilization than segregation.
-
Design for failure: With tens of thousands of machines, something is always failing. Borg achieves 99.99% availability through replication, isolation, and defensive design.
-
The scheduler is critical: Clever optimizations like equivalence classes and relaxed randomization make the difference between scheduling taking minutes vs. days.
-
Lessons transfer: Many of Borg's insights directly shaped Kubernetes, which you likely use today. Understanding Borg helps you understand why Kubernetes works the way it does.
Further Reading
- Original Paper
- Annotated copy
- Related papers on this blog: Omega (Borg's experimental successor), Mesos (alternative architecture), Google File System, Bigtable
Over the next few Saturdays, I'll be going through some of the foundational papers in Computer Science, and publishing my notes here. This is #17 in this series.