Chubby: Lock Service for Loosely-coupled Distributed Systems
Abstract
We describe our experiences with the Chubby lock service, which is intended to provide coarse-grained locking as well as reliable (though low-volume) storage for a loosely-coupled distributed system. Chubby provides an interface much like a distributed file system with advisory locks, but the design emphasis is on availability and reliability, as opposed to high performance. Many instances of the service have been used for over a year, with several of them each handling a few tens of thousands of clients concurrently. The paper describes the initial design and expected use, compares it with actual use, and explains how the design had to be modified to accommodate the differences.
What Problem Does Chubby Solve?
Imagine you have hundreds or thousands of servers working together to provide a service (like Google Search or Gmail). These systems need to coordinate with each other - for example, deciding which server should be the "leader" that makes important decisions, or where to store critical configuration information that all servers need to access.
Chubby is Google's solution to this coordination problem. Think of it as a highly reliable librarian that holds onto important information and makes sure everyone gets the same answer when they ask "who's in charge?" or "what's the current configuration?"
Introduction
What kind of system is Chubby designed for?
Chubby is built for loosely-coupled distributed systems - think of hundreds or thousands of servers that need to work together but don't need to be tightly synchronized all the time. These servers are connected by a high-speed network (like within a data center).
What are Chubby's priorities?
The design focuses on three main goals:
- Reliability - it must work correctly even when things go wrong
- Availability - it should be accessible whenever clients need it
- Easy-to-understand semantics - developers shouldn't need a PhD to use it correctly
Performance (throughput) and storage capacity were considered less important than these goals.
What does Chubby's interface look like?
Chubby behaves like a simple file system where you can read and write entire files. But it adds two important features:
- Advisory locks - think of these as "reserved" signs you can put on files to coordinate who can access them
- Event notifications - Chubby can alert you when important things happen (like when a file gets modified)
How is Chubby used at Google?
Real systems at Google rely heavily on Chubby:
- Google File System uses Chubby to elect which server should be the master (the one making decisions)
- Bigtable uses Chubby for several purposes: electing a master, helping the master discover worker servers, and helping clients find the master
- Both systems also use Chubby as a trusted place to store critical configuration data - essentially using it as the foundation of their distributed architecture
The secret sauce: Paxos
Under the hood, Chubby uses the Paxos protocol to achieve consensus. Paxos is an algorithm that helps multiple servers agree on a single value even when some servers fail or network connections drop. It's like a voting system that guarantees everyone sees the same result, even if some voters are temporarily unavailable.
Design Decisions
The Chubby team made several important design choices. Here's why they chose what they did:
1. Lock service vs. consensus library
They built a lock service (a centralized system that manages locks) rather than giving each application its own consensus library. Why? Because a centralized service is easier to maintain and update - you fix bugs in one place rather than requiring every application to update their libraries.
2. Store small files, not just locks
Chubby can serve small files to let elected leaders advertise themselves and their configuration. This meant they didn't need to build a separate service just for storing this information. It's like having a bulletin board where the leader can post "I'm in charge, here's my phone number."
3. Scale to thousands of clients
When a leader advertises itself via a Chubby file, thousands of clients might need to read it. So Chubby had to support thousands of simultaneous readers efficiently, without requiring lots of servers.
4. Event notifications instead of polling
Rather than forcing clients to constantly ask "has anything changed?" (polling), Chubby provides event notifications - it tells you when something important happens. This is much more efficient, like getting a text message when your package arrives rather than checking your doorstep every minute.
5. Caching for performance
Even with notifications, many developers will write code that repeatedly reads the same files. So Chubby includes caching - storing frequently-accessed data closer to clients for faster access.
6. Consistent caching (no surprises)
Caching can be tricky - if you read stale data, your application might make wrong decisions. Chubby uses consistent caching, ensuring that when data changes, all cached copies are updated. This prevents confusing bugs that happen when different parts of your system see different values.
7. Security and access control
The paper mentions avoiding "financial loss and jail time" - a tongue-in-cheek way of saying that Google's data is valuable and regulated. Chubby includes access control to ensure only authorized services can access sensitive data.
8. Coarse-grained locks (not fine-grained)
This might be the most surprising choice: Chubby is designed for locks held for minutes to hours, not seconds or milliseconds.
Why? Fine-grained locks (held briefly, acquired frequently) would overwhelm a centralized lock service. Coarse-grained locks are much easier to manage - the lock server doesn't care if you're processing one transaction per second or a thousand, as long as you keep the same lock the whole time.
System Structure
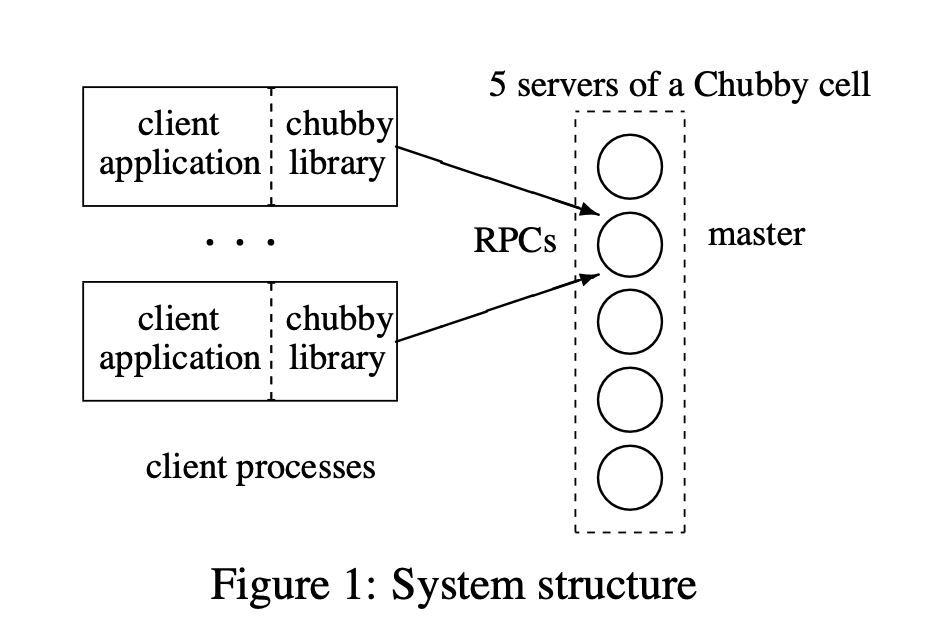
Chubby's architecture is designed for high availability through replication. Here's how it works:
Client library handles all communication
All interactions between applications and Chubby go through a client library. This library handles the complexity of finding servers, retrying failed requests, and managing sessions.
Election of a master server
Chubby typically runs with 5 replica servers (copies of the system). These replicas use a consensus protocol (Paxos) to elect one master server that handles all requests.
To become master, a server needs:
- Votes from a majority of replicas (at least 3 out of 5)
- Promises from those replicas that they won't elect a different master for a few seconds (called the master lease)
Think of this like a democratic election where the winner needs a majority vote, and voters promise not to hold another election for a short time.
Finding the master
How do clients know which server is the master? They send "who's the master?" requests to the replicas listed in DNS (like a phone book). The replicas respond with the current master's address.
Reading and writing data
The master handles all read and write requests. Reads are fast because only the master needs to respond. As long as the master lease hasn't expired, we're guaranteed no other server thinks it's the master, so reading from just the master is safe.
Recovering from failures
If the master fails: The other replicas notice when their master lease expires. They run a new election, and typically elect a new master within a few seconds. This is why having multiple replicas is so important!
If a non-master replica fails: If a replica is down for several hours, an automated system kicks in. It grabs a fresh machine from a pool of available servers, installs the Chubby software, and updates DNS to point to the new replica instead of the failed one.
Components
Here are the key building blocks that make Chubby work:
Locks and Sequencers
Every file and directory in Chubby can act as a reader-writer lock:
- Exclusive (writer) mode: Only one client can hold the lock - like having the only key to a room
- Shared (reader) mode: Multiple clients can hold the lock simultaneously - like a library where many people can read the same book
These are advisory locks, meaning Chubby won't physically prevent you from accessing a file without the lock - it's up to your application to check and respect the locks. Think of them as "Please don't disturb" signs rather than actual locked doors.
Events (Notifications)
Chubby can notify clients when important things happen. The most useful events are:
- File contents modified
- Child node added, removed, or modified
- Chubby master failed over (new leader elected)
- A handle has become invalid
- Lock acquired
- Conflicting lock request from another client
The authors note that some of these (the last two) turned out to be rarely used and probably shouldn't have been included.
API (How you interact with Chubby)
Clients interact with Chubby through handles - think of these as references to open files or directories. Key operations include:
Open()andClose()- open and close filesPoison()- marks a handle as invalid, causing operations to fail (useful for canceling operations safely)GetContentsAndStat()/GetStat()- read file contents and metadataReadDir()- list directory contentsSetContents()/SetACL()/Delete()- modify files and permissionsAcquire()/TryAcquire()/Release()- lock operationsGetSequencer()/SetSequencer()/CheckSequencer()- advanced lock verification
Caching
To improve performance, clients cache file data and metadata locally. But here's the clever part: when the master needs to modify data, it first sends invalidation messages to all clients that might have cached that data. The modification is blocked until all those clients confirm they've invalidated their caches. This ensures consistency - no one sees stale data.
These invalidation messages piggyback on KeepAlive RPCs (regular heartbeat messages between clients and servers).
Sessions and KeepAlives
A session represents an active connection between a client and the Chubby system. Sessions are maintained through periodic KeepAlive messages - like a heartbeat that says "I'm still here!"
If a client stops sending KeepAlives (maybe it crashed), Chubby eventually times out the session and releases any locks the client held.
Fail-overs (Switching to a new master)
When a master fails or loses leadership, it throws away its in-memory state (sessions, handles, locks). The new master rebuilds this state based on what's stored in the replicated database, plus information from clients reconnecting.
Database Implementation
Chubby originally used Berkeley DB (a proven database library) in a replicated configuration. An important optimization: since Chubby doesn't have path-based permissions (no "/home/user/files" style permissions), each file access only requires a single database lookup, keeping things fast.
Backup
Every few hours, the master writes a complete snapshot of its database to Google File System (GFS) in a different building. This protects against catastrophic failures like a fire or power outage taking down an entire data center.
Mirroring
Chubby can mirror (copy) files to multiple locations. This is mainly used for configuration files that need to be available across Google's global data centers - think of distributing the same settings to computing clusters around the world.
Mechanisms for Scaling
Chubby faces an interesting scaling challenge: each client is an individual process (not a machine), so one physical machine might run many processes that each connect to Chubby. In practice, Google has seen single Chubby masters handling 90,000 simultaneous clients - far more connections than there are physical machines!
To scale even further, the authors designed two mechanisms (though they weren't in production yet at the time of writing):
Proxies
Think of a proxy as a middleman between clients and the Chubby master. Instead of 90,000 clients connecting directly to the master, maybe 100 proxies connect to the master, and each proxy serves 900 clients. This dramatically reduces load on the master while still serving all clients.
Partitioning
Split the data across multiple Chubby cells (independent Chubby systems), so different applications use different cells. It's like having multiple independent lock services instead of one giant one. This is only practical when different applications don't need to share the same locks or files.
Use, Surprises and Design Errors
Real-world usage revealed several surprises and important lessons:
1. Used as a name server (biggest surprise!)
Even though Chubby was designed primarily as a lock service, its most popular use turned out to be as a name server - a place to store and look up information like "which server is the master?" or "what's the configuration for service X?"
This makes sense in retrospect: the reliable storage and notification features made Chubby perfect for this use case. If the authors had foreseen this, they would have implemented proxies sooner to handle the read-heavy workload more efficiently.
2. Abusive clients (the importance of resource reviews)
Some applications used Chubby in ways that didn't scale well. The key lesson: when reviewing a new Chubby use case, check whether resource usage grows linearly (or worse) with the number of users or amount of data.
For example:
- Bad: Creating one Chubby file per user (1 million users = 1 million files)
- Good: Creating one Chubby file per service (10 services = 10 files)
Any pattern where load grows linearly needs "compensating parameters" - limits that keep resource usage reasonable.
3. Developers rarely consider availability
There's an important but subtle difference between:
- A service being up (running and responding to pings)
- A service being available to your application (your app can actually use it)
Network issues, misconfigurations, or firewall rules might prevent your application from reaching Chubby even when Chubby itself is fine. Many developers didn't account for this, leading to application failures when network issues occurred.
4. TCP vs UDP for KeepAlives (a low-level protocol issue)
Initially, Chubby sent KeepAlive messages over TCP (the reliable protocol most of the internet uses). But there's a problem: TCP has its own timeout and retry logic that doesn't know about Chubby's session leases.
During network congestion, TCP would keep retrying and backing off, causing KeepAlive messages to arrive too late. By the time TCP finally delivered the message, Chubby had already killed the session for timing out!
The solution: switch to UDP (a simpler, unreliable protocol) for KeepAlives. UDP delivers messages immediately or not at all - no hidden retries that delay delivery. The trade-off is that UDP doesn't have congestion control, so it should only be used when timing guarantees are critical (like KeepAlives).
Summary
Chubby is Google's distributed lock service, originally designed for coarse-grained synchronization - helping different parts of large distributed systems coordinate their activities. Think of it as the system that answers questions like "who's the leader?" and "what's the current configuration?"
In practice, Chubby became much more than just a lock service. Its most common use turned out to be as a name server and configuration repository - a highly reliable place to store and retrieve critical information that many systems need to access.
Key takeaways:
- Availability over performance: Chubby prioritizes being reliably available over raw speed
- Coarse-grained locks: Designed for locks held for minutes/hours, not milliseconds
- Replication for reliability: Uses 5 replicas with Paxos consensus to stay available even when servers fail
- File-system interface: Familiar file/directory abstraction makes it easy to use
- Caching with consistency: Aggressively caches data while maintaining consistency through invalidations
- Real-world lessons: Usage patterns often differ from initial designs - flexibility is valuable
Chubby has been a foundational piece of Google's infrastructure, used by critical systems like GFS and Bigtable. Its design influenced later systems like Apache Zookeeper, which brought similar coordination capabilities to the broader open-source community.
Over the next few Saturdays, I'll be going through some of the foundational papers in Computer Science, and publishing my notes here. This is #9 in this series.