The Google File System
Introduction
The Google File System (GFS) paper, published in 2003, describes how Google built a storage system to handle massive amounts of data across thousands of computers. This was a groundbreaking paper that influenced many modern distributed storage systems like HDFS (Hadoop Distributed File System).
Why does this matter? In the early 2000s, Google needed to store and process vast amounts of web data for search indexing. Traditional file systems weren't designed for this scale. GFS solved this problem by building a distributed file system that could store petabytes of data across cheap, unreliable hardware.
Abstract
We have designed and implemented the Google File System, a scalable distributed file system (a file system that spreads data across many computers) for large distributed data-intensive applications. It provides fault tolerance (continues working even when parts fail) while running on inexpensive commodity hardware (standard, affordable computers rather than expensive specialized machines), and it delivers high aggregate performance to a large number of clients. While sharing many of the same goals as previous distributed file systems, our design has been driven by observations of our application workloads and technological environment, both current and anticipated, that reflect a marked departure from some earlier file system assumptions. This has led us to reexamine traditional choices and explore radically different design points. The file system has successfully met our storage needs. It is widely deployed within Google as the storage platform for the generation and processing of data used by our service as well as research and development efforts that require large data sets. The largest cluster to date provides hundreds of terabytes of storage across thousands of disks on over a thousand machines, and it is concurrently accessed by hundreds of clients. In this paper, we present file system interface extensions designed to support distributed applications, discuss many aspects of our design, and report measurements from both micro-benchmarks and real world use.
Key Concepts and Design
Design Constraints and Assumptions
Google made several important observations about their workload that shaped GFS's design. These assumptions were different from traditional file systems, which is what made GFS innovative:
-
Component failures are the norm rather than the exception: When you have thousands of machines, something is always breaking. Google saw problems caused by application bugs, operating system bugs, human errors, and the failures of disks, memory, connectors, networking, and power supplies. Therefore, constant monitoring, error detection, fault tolerance, and automatic recovery must be integral to the system. The system assumes failure will happen and is designed to handle it gracefully.
-
Files are huge by traditional standards: Multi-gigabyte files are common. Think about web crawl data or search index files - these can be tens or hundreds of gigabytes. Traditional file systems were optimized for smaller files (documents, images, etc.).
-
Most files are mutated by appending new data rather than overwriting existing data: Random writes within a file are practically non-existent. Once written, the files are only read, and often only sequentially. For example, when building a search index, you typically add new pages you've crawled rather than changing old ones. Given this access pattern on huge files, appending becomes the focus of performance optimization and atomicity guarantees, while caching data blocks in the client loses its appeal.
-
Co-designing the applications and the file system API benefits the overall system by increasing flexibility: Google controlled both the applications using GFS and the file system itself. This allowed them to make tradeoffs that wouldn't work for a general-purpose file system. For example, they have relaxed GFS's consistency model (explained later) to vastly simplify the file system without imposing an onerous burden on the applications. They have also introduced an atomic append operation so that multiple clients can append concurrently to a file without extra synchronization between them.
-
The workloads primarily consist of two kinds of reads: large streaming reads (reading gigabytes of data sequentially, like processing a web crawl) and small random reads (looking up specific pieces of information, like checking if a URL has been seen before).
-
Files are often used as producer-consumer queues or for many-way merging: One program writes data, multiple others read and process it.
-
High sustained bandwidth is more important than low latency: When processing terabytes of data, it's more important to maintain a high throughput (moving lots of data per second) than to have quick response times for individual operations. This is a key tradeoff - they optimized for batch processing rather than interactive use.
File System Interface
GFS provides the familiar file operations you'd expect (create, delete, open, close, read, and write), but adds two special operations designed for Google's use cases:
-
Snapshot: Creates a copy of a file or entire directory tree at low cost. This is useful for creating backups or checkpoints without copying all the data immediately. Think of it like a "save point" in a video game.
-
Record Append: This is the killer feature for Google's workload. It allows multiple clients to append data to the same file concurrently while guaranteeing the atomicity of each individual client's append. Atomicity means each append either fully succeeds or fully fails - you never get partial writes mixed together. This is perfect for scenarios like multiple web crawlers writing URLs to the same file, or multiple machines writing log entries to a shared log file.
Architecture Overview
GFS has a simple yet elegant architecture with three main components:
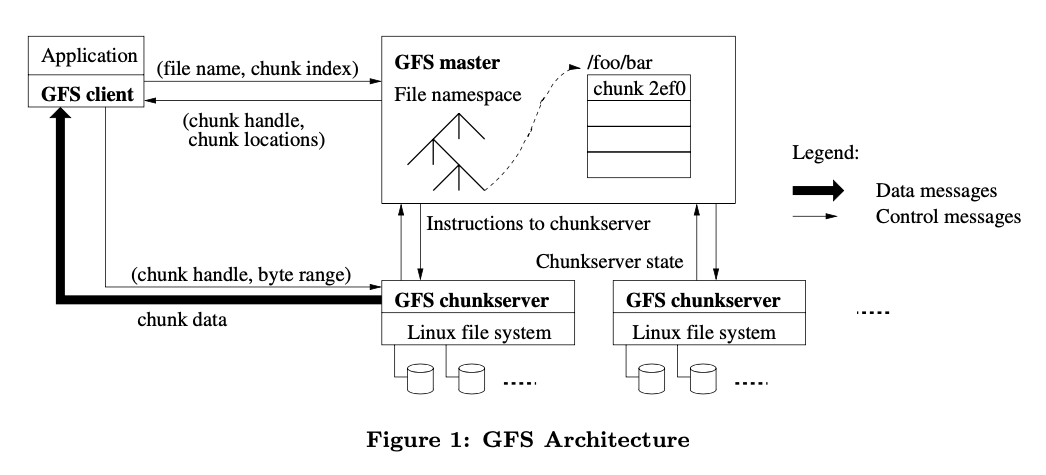
The Three Components:
- A Single Master: The brain of the system that keeps track of everything but doesn't handle the actual data
- Multiple Chunkservers: Worker machines that store the actual file data
- Multiple Clients: Applications that read and write files
How Files Are Stored:
Files in GFS are split into fixed-size 64MB chunks (think of them as large puzzle pieces). Each chunk gets a unique 64-bit identifier (called a chunk handle) when it's created. By default, each chunk is stored on three different chunkservers for redundancy - if one machine fails, the data is still available on two others.
The Master's Role:
The master maintains all file system metadata - essentially the "table of contents" for the entire file system. This includes:
- The namespace (file and directory structure)
- Access control information (who can read/write what)
- The mapping from files to chunks (which chunks make up each file)
- The current locations of chunks (which chunkservers have which chunks)
The master also controls system-wide activities such as chunk lease management, garbage collection of orphaned chunks, and chunk migration between chunkservers.
Client-Server Communication:
Here's a clever design choice: clients interact with the master for metadata operations, but all data-bearing communication goes directly to the chunkservers. This means:
- Client asks master: "Where is the data for file X?"
- Master responds: "Chunks A, B, C are on servers 1, 2, 3"
- Client talks directly to those chunkservers to read/write data
This prevents the master from becoming a bottleneck when transferring large amounts of data.
Caching Decisions:
Neither the client nor the chunkserver caches file data. This seems counterintuitive, but makes sense for Google's workload. Client caches offer little benefit because most applications stream through huge files (reading them once sequentially) or have working sets too large to be cached in memory. However, clients do cache metadata (the location information) so further reads of the same chunk require no more client-master interaction until the cached information expires or the file is reopened. The client typically asks for multiple chunks in the same request and the master can also include the information for chunks immediately following those requested.
Chunk Size Considerations:
The 64MB chunk size is much larger than typical file system block sizes (4KB-8KB). This has tradeoffs:
- Benefit: Reduces the number of chunks the master needs to track, reduces client-master communication
- Potential Problem: Small files could become hot spots - if many clients access a small file (one chunk), the few chunkservers storing it get overwhelmed
- Solution: Store popular small files (like executable binaries) with a higher replication factor and stagger application start times
Lazy space allocation avoids wasting space due to internal fragmentation, which would be significant with such large chunks.
Metadata Management:
The master tracks three major types of metadata:
- The file and chunk namespaces (directory structure)
- The mapping from files to chunks
- The locations of each chunk's replicas
Interestingly, the master does not store chunk location information persistently on disk. Instead, it asks each chunkserver about its chunks at master startup and whenever a chunkserver joins the cluster. This eliminated the problem of keeping the master and chunkservers in sync as chunkservers join and leave the cluster, change names, fail, restart, and so on. In a cluster with hundreds of servers, these events happen all too often.
The Operation Log:
The operation log is critical - it contains a historical record of all metadata changes. Not only is it the only persistent record of metadata, but it also serves as a logical timeline that defines the order of concurrent operations. They replicate it on multiple remote machines and respond to a client operation only after flushing the corresponding log record to disk both locally and remotely. This ensures durability - even if the master crashes, it can replay the log to reconstruct the metadata.
Consistency Guarantees:
GFS makes specific guarantees about data consistency:
-
File namespace mutations (e.g., file creation, deletion) are atomic. They are handled exclusively by the master: namespace locking guarantees atomicity and correctness; the master's operation log defines a global total order of these operations.
-
Record appends are interesting: the data is appended atomically at least once even in the presence of concurrent mutations, but at an offset of GFS's choosing. This means your data will definitely be written once, but you might not know exactly where, and in rare failure cases it might be duplicated.
GFS has a relaxed consistency model - it doesn't guarantee that all replicas are always identical at every moment, or that all clients see changes instantly. However, GFS applications can work with this model using techniques like:
- Relying on appends rather than overwrites
- Checkpointing (saving progress markers)
- Writing self-validating, self-identifying records (each record contains checksums and metadata so you can detect and skip duplicates or corruption)
Leases and Mutation Order:
When data needs to be written or modified, each mutation is performed at all the chunk's replicas. They use leases to maintain a consistent mutation order across replicas:
- The master grants a chunk lease to one of the replicas, called the primary
- The primary picks a serial order for all mutations to the chunk
- All replicas follow this order when applying mutations
This ensures that even though there are multiple copies, they all see the same sequence of changes.
Data Flow and Write Operations
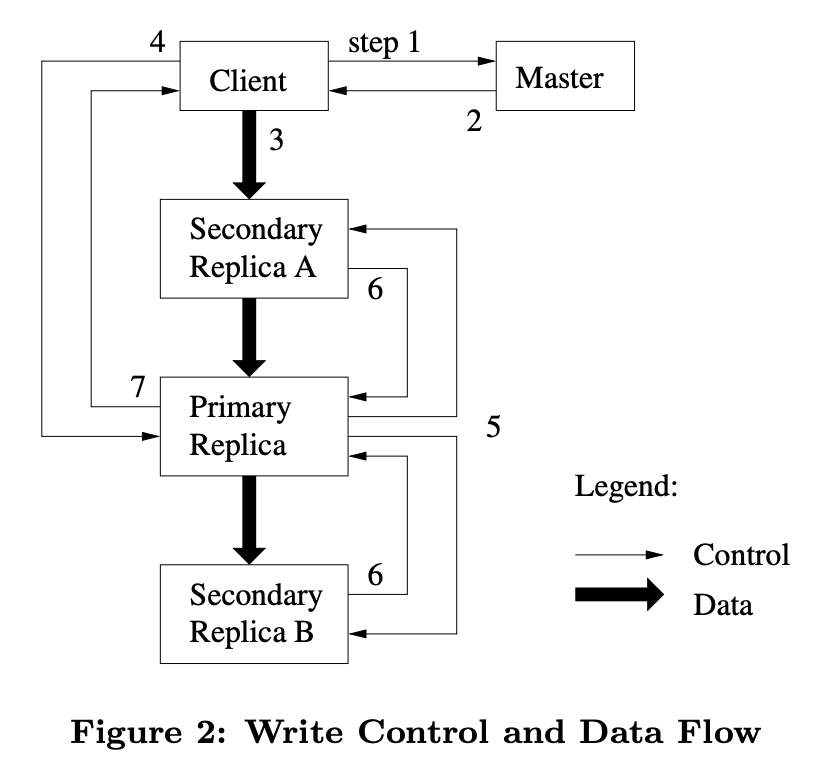
Optimizing Network Usage:
To fully utilize each machine's network bandwidth, GFS uses a clever trick: the data is pushed linearly along a chain of chunkservers rather than distributed in some other topology (e.g., a tree where the client sends to multiple servers). Here's how it works:
- Client sends data to the nearest chunkserver
- That chunkserver forwards it to the next nearest one
- And so on, forming a pipeline
This way, each machine's full outbound bandwidth is used to transfer the data as fast as possible rather than divided among multiple recipients. The network topology is simple enough that "distances" can be accurately estimated from IP addresses (servers on the same rack are "closer" than servers in different data centers).
Key System Features
Namespace Management and Locking:
The master uses a sophisticated locking scheme to allow concurrent operations. Each master operation acquires a set of locks before it runs. For example, if an operation involves the path /d1/d2/.../dn/leaf, it will acquire read-locks on all the directory names (/d1, /d1/d2, ..., /d1/d2/.../dn), and either a read lock or a write lock on the full pathname /d1/d2/.../dn/leaf.
One nice property of this locking scheme is that it allows concurrent mutations in the same directory. For example, multiple file creations can be executed concurrently in the same directory: each acquires a read lock on the directory name and a write lock on the file name. This is like multiple people adding different files to the same folder simultaneously.
To prevent deadlock (a situation where operations are waiting for each other indefinitely), locks are acquired in a consistent total order: they are first ordered by level in the namespace tree and lexicographically (alphabetically) within the same level.
Garbage Collection:
After a file is deleted, GFS does not immediately reclaim the available physical storage - this is called lazy deletion. It does so only during regular garbage collection at both the file and chunk levels. This approach makes the system much simpler and more reliable:
- Garbage collection provides a uniform and dependable way to clean up any replicas not known to be useful
- It merges storage reclamation into the regular background activities of the master, such as the regular scans of namespaces and handshakes with chunkservers
- It's done in batches and the cost is amortized (spread out over time)
- The delay in reclaiming storage provides a safety net against accidental, irreversible deletion (similar to your computer's trash/recycle bin)
High Availability:
Google keeps the overall system highly available with two simple yet effective strategies:
-
Fast recovery: Both the master and chunkservers are designed to restore their state and start in seconds, regardless of how they terminated. There's no distinction between normal and abnormal termination.
-
Replication: All data is replicated across multiple chunkservers (default 3 copies). The master itself is replicated, and its operation log is replicated on multiple machines.
Data Integrity:
With thousands of disks, disk corruption is inevitable. Each chunkserver uses checksumming to detect corruption of stored data. Each 64KB block of a chunk has a corresponding 32-bit checksum. Before reading data, the chunkserver verifies the checksum. If there's a mismatch, the chunkserver returns an error and the client tries a different replica.
Real-World Challenges and Lessons
Building a system at Google's scale revealed interesting problems that you might not encounter in smaller systems:
Hardware Reliability Issues
Some of the biggest problems were disk and Linux related. Many of the disks claimed to the Linux driver that they supported a range of IDE protocol versions but in fact responded reliably only to the more recent ones. In other words, the disks were lying about their capabilities! This problem motivated the use of checksums to detect data corruption, while Google concurrently modified the Linux kernel to handle these protocol mismatches.
Lesson: When you're using thousands of commodity hardware components, manufacturer specifications aren't always accurate. You need defensive programming and data validation at the application level.
Operating System Bottlenecks
Another Linux problem was a single reader-writer lock that any thread in an address space must hold when it pages in from disk (reader lock) or modifies the address space in an mmap() call (writer lock).
The Google team saw transient timeouts in the system under light load and looked hard for resource bottlenecks or sporadic hardware failures. Eventually, they discovered that this single lock blocked the primary network thread from mapping new data into memory while the disk threads were paging in previously mapped data.
Since GFS is mainly limited by the network interface rather than by memory copy bandwidth, they worked around this by replacing mmap() with pread() at the cost of an extra copy. This means copying data one extra time in memory, which uses more CPU but avoids the lock contention.
Lesson: Sometimes the bottleneck isn't where you expect it. Operating system primitives that work fine for typical applications can become problems at scale. Performance debugging requires careful instrumentation and patience.
Key Takeaways
If you remember nothing else from this paper, remember these core ideas:
-
Design for your specific workload: GFS made unconventional choices (huge chunks, relaxed consistency, append-only writes) because they fit Google's specific needs. Don't blindly copy architectural patterns - understand your own requirements first.
-
Assume failure is normal: When you have thousands of machines, something is always broken. Design systems that assume components will fail and can handle it gracefully through replication and automatic recovery.
-
Separate metadata from data: Having the master handle only metadata while clients communicate directly with chunkservers for data prevents bottlenecks.
-
Simple can be better: GFS made many simplifying assumptions (single master, relaxed consistency) that could have been deal-breakers in other contexts but worked well for Google's use case.
-
Co-design applications and infrastructure: Google could make GFS's consistency model weaker because they controlled the applications using it. This tight integration allowed for better overall system performance.
Impact and Legacy
The Google File System paper influenced an entire generation of distributed storage systems:
- Hadoop HDFS: Directly inspired by GFS, implementing many of the same concepts for the open-source ecosystem
- Cloud Storage: Many concepts from GFS appear in modern cloud storage systems
- BigTable, MapReduce: Other Google systems were built on top of GFS, forming the foundation of Google's data processing infrastructure
While GFS itself has been replaced internally at Google by newer systems (like Colossus), the lessons and design principles from this paper remain relevant for anyone building distributed systems.
Further Reading
Over the next few Saturdays, I'll be going through some of the foundational papers in Computer Science, and publishing my notes here. This is #4 in this series.