Hints for Computer System Design
About This Paper
This influential 1983 paper by Butler Lampson, a Turing Award-winning computer scientist, distills decades of experience building groundbreaking systems at Xerox PARC. The paper presents practical advice for designing computer systems, drawn from real projects including:
- Xerox Alto: One of the first personal computers (1973), featuring a graphical user interface and mouse
- Dorado: A powerful personal workstation with performance comparable to mainframe computers of its era
- Bravo: The first WYSIWYG (What You See Is What You Get) text editor, which later inspired Microsoft Word
- Xerox Star: An early office automation system with a desktop metaphor
These systems were revolutionary in the 1970s and 1980s, laying the groundwork for modern personal computing. Lampson's "hints" aren't strict rules, but rather hard-won lessons about what works (and what doesn't) when building complex systems.
Abstract
Studying the design and implementation of a number of computer systems has led to some general hints for system design. They are described here and illustrated by many examples, ranging from hardware such as the Alto and the Dorado to application programs such as Bravo and Star.
Introduction
The Philosophy: Lampson acknowledges there's rarely a single "best" way to build any system. Instead, the goal is to avoid terrible design choices and establish clear separation of responsibilities between different parts of the system.
This paper focuses on practical advice rather than abstract methodology. Lampson deliberately avoids repeating well-known concepts like modularity or top-down design, instead offering specific, experience-based guidance. He also warns against blindly following popular design methods without understanding their trade-offs.
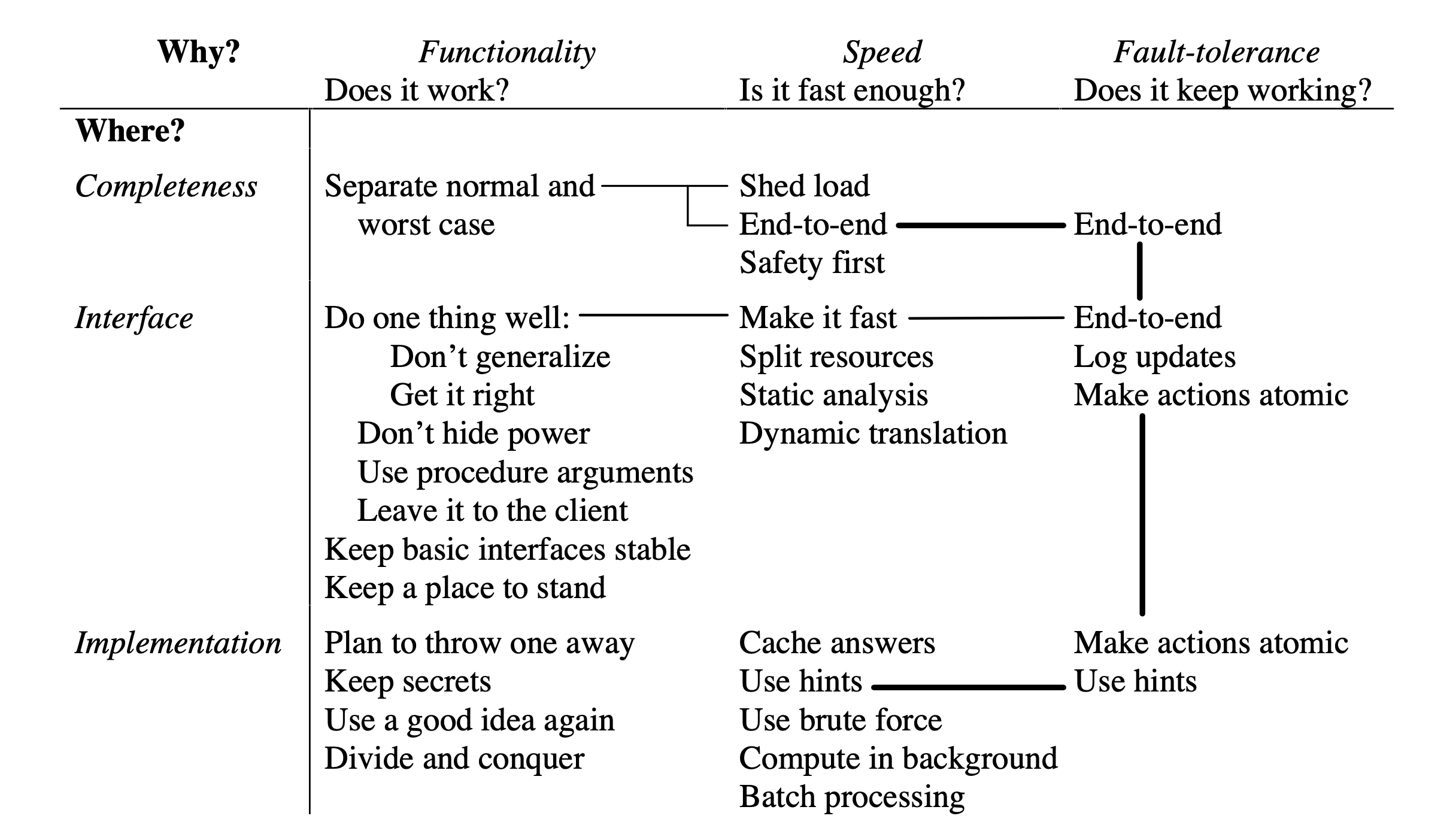
How This Paper is Organized: The hints are organized along two dimensions:
-
Why it helps - Does it improve:
- Functionality: Does the system work correctly?
- Speed: Is it fast enough?
- Fault-tolerance: Does it keep working when things go wrong?
-
Where it applies - Does it help with:
- Completeness: Making sure the system does everything it needs to do
- Interfaces: How different parts of the system communicate
- Implementation: The internal workings of each part
Functionality
This section focuses on making systems that actually work correctly. The key challenge is designing good interfaces - the boundaries where different parts of a system meet and interact.
Why Interfaces Are Hard: An interface is essentially the set of assumptions that each programmer makes about how another part of the system behaves. Good interface design must balance three competing goals:
- Simplicity: Easy to understand and use
- Completeness: Provides all necessary functionality
- Efficiency: Can be implemented quickly and with minimal overhead
Think of an interface like a programming language - it defines objects and the operations you can perform on them. This is why interface design is so challenging.
Keep it Simple
The Problem: Users of an interface depend on it having reasonable performance costs, but these costs are rarely documented. When multiple layers of abstraction each add "just" 50% overhead, the cumulative effect is dramatic. Six layers of 50% overhead each result in more than 10x slowdown (1.5^6 = 11.4x).
The Solution: Follow the KISS principle - "Keep It Simple, Stupid." When in doubt, leave it out. Don't add features unless you're certain they're needed.
Exterminate Features
Don't add features that only benefit a few users if implementing them slows down everyone else. Maybe future implementers with better understanding will find an efficient way to add those features, but if you can't do it efficiently now, don't do it at all. It's better to start with less and add carefully than to bloat your system from the beginning.
Get it Right
Abstraction and simplicity are important, but they don't excuse correctness problems. Don't hide bugs behind elegant abstractions. Even beautiful, simple designs must actually work correctly.
Make it Fast, Not Powerful
The Trade-off: Slow, powerful operations sound appealing, but they force users who only need basic functionality to pay a performance penalty for features they don't use. Often, the "powerful" operation isn't even what most users need.
Real-World Example: Early RISC processors (like the IBM 801) with simple, fast instructions could run programs faster than complex processors (like the VAX) with powerful but slower instructions - even when using the same amount of hardware. This is because most programs spend most of their time doing simple operations.
Don't Hide Power
When a lower level of abstraction can do something efficiently, don't bury that efficiency inside a slower, more general higher-level abstraction. Abstractions should hide complexity and undesirable properties, but they shouldn't hide performance. If your underlying system can do something fast, let users access that speed.
Example: Allow clients to pass custom functions (procedure arguments) for filtering or processing data, rather than forcing them to use a limited pattern-matching language you've defined. This gives flexibility without sacrificing performance.
Leave it to the Client
When passing control between components is cheap, your interface can achieve simplicity, flexibility, and high performance simultaneously by doing one thing well and letting clients handle the rest.
Examples:
- Monitors (a concurrency primitive): The locking and signaling mechanisms are minimal, leaving all the real work to client code. This simplicity is key to their success.
- Unix philosophy: Small programs that read input streams, write output streams, and do one operation well. They can be combined in powerful ways, but each remains simple.
Continuity: Keep Interfaces Stable
Once you publish an interface, changing it becomes extremely difficult, especially in systems without type-checking where you can't automatically find all the places that depend on it. As systems grow beyond 250,000 lines of code, even necessary changes become prohibitively expensive to implement.
Rule of thumb: Only programming language and operating system kernel interfaces traditionally receive this level of stability commitment. Think carefully before promising similar stability elsewhere.
When you must change: Keep a "place to stand" - a way to support both old and new versions simultaneously. For example, world-swap debuggers work by swapping the entire memory contents between the running system and the debugger, allowing you to debug without modifying the original system.
Making Implementations Work
Plan to throw one away: You're going to end up rewriting it anyway, so plan for a prototype from the start. This costs far less than pretending your first version will be the final one.
Keep secrets of the implementation: The interface defines what cannot change; everything else should be hidden implementation details that can change freely. The fewer assumptions different parts make about each other's internals, the easier the system is to modify.
The Performance Paradox: As one Xerox engineer noted, "An efficient program is an exercise in logical brinkmanship." You can improve performance by having parts make more assumptions about each other, which allows optimization. But this conflicts with the principle of hiding implementation details. Striking the right balance is more art than science.
Divide and Conquer
Break complex problems into manageable pieces. (Lampson assumes this is well-understood and doesn't elaborate.)
Use a Good Idea Again Instead of Generalizing It
When you have a solution that works, it's often better to reuse the same simple approach in multiple places rather than building one complex, general solution.
Example: Replication (keeping multiple copies of data) can be implemented as a simple local mechanism in several places - for storing transaction logs reliably, for ensuring commit records survive, etc. Using the same simple idea multiple times is easier to understand and implement than building a general-purpose replication framework.
Handle Normal and Worst Cases Separately
Normal cases and worst cases have different requirements:
- Normal case: Must be fast
- Worst case: Just needs to make some progress
Controversial Example: Sometimes it's acceptable to crash processes or even the entire system as recovery from worst-case scenarios. One crash per week might be a worthwhile trade-off for 20% better performance in normal operation. (This was more acceptable in the 1980s than it would be today!)
Speed
This section covers techniques for making systems fast. Performance matters not just for user experience, but because slow systems often become unusable systems.
Split Resources Rather Than Share Them
The Principle: When in doubt, give each task its own dedicated resources rather than trying to share resources dynamically.
Why it works: Sharing requires coordination, which adds overhead. When hardware is cheap, dedicating resources (like separate I/O channels or floating-point coprocessors) often yields better performance than clever sharing schemes. Modern examples include having multiple CPU cores instead of time-sharing a single core.
Use Static Analysis When Possible
Pre-compute instead of computing on the fly: Compilers are the classic example - they translate human-readable code into fast machine code ahead of time. More generally, when you have data in a convenient format (easy to read, modify, or display), consider translating it once into a format that's fast to process, rather than translating it every time you need it.
Cache Answers to Expensive Computations
Instead of recalculating the same thing repeatedly, save the answer and reuse it.
Challenges:
- Invalidation: If the function can return different results for the same inputs (it's not "pure"), you need a way to invalidate stale cache entries.
- Size management: A cache too small for all active values will "thrash" (constantly evicting and recomputing values). Make cache size adaptive - grow it when hit rates drop, shrink it when entries go unused.
Use Hints to Speed Up Normal Execution
What's a hint?: Like a cache entry, but with two key differences:
- It might be wrong (you must verify it)
- You don't look it up by key - you have it already
Example: Storing an expected file location as a hint. Most of the time it's correct and you find the file immediately. If it's wrong, you fall back to searching, but you're no worse off than if you hadn't had the hint.
When in Doubt, Use Brute Force
As hardware gets cheaper, a simple solution that uses lots of computing power is often better than a complex, "clever" solution that only works well under specific assumptions. Straightforward code is easier to understand, maintain, and verify.
Compute in Background When Possible
For interactive systems: Minimize work before responding to user requests. Respond quickly with partial results, then complete the work in the background.
Why it works:
- Users prefer fast response times
- System load varies - there's usually idle time later to finish the work
Use Batch Processing When Possible
Processing multiple similar operations together is often more efficient than processing them one at a time. (Lampson doesn't elaborate, assuming this is well-known.)
Safety First: Avoid Disaster Over Seeking Optimal
The Reality: General-purpose systems cannot optimize resource allocation perfectly. Experience with virtual memory, networks, disk allocation, and databases proves this repeatedly.
The Strategy: Design for the worst case. Avoid catastrophic failure rather than chasing optimal performance.
Interesting Historical Ideas:
- Bob Morris's "Big Red Button": Each terminal should have a button users press when service is unsatisfactory. The system must either improve service or disconnect the user. This prevents people from wasting time at terminals that aren't delivering value.
- ARPANET's failed guarantee: Early ARPANET guaranteed packet delivery unless a machine was down or a node failed while holding the packet. This turned out to be a bad idea - it made avoiding deadlock nearly impossible and added complications even in normal cases. Worse, clients had to handle lost packets anyway (see the end-to-end principle below), so the guarantee provided no real benefit. It was eventually abandoned.
Key insight: "The unavoidable price of reliability is simplicity." Complex systems fail in complex ways.
Fault-tolerance
Building reliable systems isn't inherently difficult if you design for reliability from the start. However, adding reliability to an existing system after the fact is extremely hard. These hints show how to build systems that keep working even when things go wrong.
The End-to-End Principle
The Core Idea: Error recovery at the application level is absolutely necessary for reliability. Any error detection or recovery at lower levels is optional - it's only there for performance, not correctness.
Real Example: The Cambridge ring-based system routinely copies entire 58 MB disk packs with only an end-to-end verification check. Errors are so rare that the 20-minute copy operation almost never needs repeating. They skip intermediate checks because the final check is sufficient.
Why it matters: Lower levels of the system (networks, operating systems, etc.) can try to prevent errors, but the application must verify correctness anyway because errors can still occur at the application level. So lower-level error checking is redundant from a correctness perspective - it just improves performance by catching errors early.
Limitations:
- Requires cheap verification: You need an inexpensive way to check if everything worked correctly.
- Performance surprises: Systems might work correctly but have terrible performance problems that don't show up until production under heavy load.
Log Updates to Record Truth
The Technique: Use a log (a simple, append-only data structure) as the authoritative record of what happened. Logs can be reliably written to disk or other stable storage that survives crashes.
How it works:
- Record every update as a log entry containing the operation name and its arguments
- The operation must be functional (deterministic) - running it with the same arguments always produces the same result, with no dependence on external state
- The current in-memory state becomes like a "hint" - it's derived from the log and can be reconstructed if lost
Beyond databases: While logs have been used in databases for years, the idea applies broadly - to file systems, configuration management, distributed systems, and more.
Make Actions Atomic or Restartable
Atomic actions (transactions): Operations that either complete entirely or have no effect. There's no partial completion - it's all or nothing.
How databases implement atomicity:
- Assign each action a unique identifier
- Label all log entries with this identifier
- Store a commit record showing whether the action is in progress, committed (done), or aborted (canceled)
- After a crash, replay committed actions and undo aborted ones
Restartable actions (idempotent operations): An operation that can be partially executed multiple times without changing the final result. For example, "set X to 5" can be run multiple times safely, but "increment X" cannot.
Practical note: While atomic actions sound complex, they're more practical than their reputation suggests. For some applications, a simpler, cheaper approach may suffice. Perfect consistency might not matter if occasional inconsistencies or delays don't significantly impact usefulness.
Key Takeaways
Butler Lampson's paper offers timeless advice for system designers, drawn from building revolutionary systems at Xerox PARC. The hints are organized around three dimensions:
- Functionality: Keep interfaces simple, eliminate unnecessary features, make them fast rather than powerful, and maintain stability
- Speed: Split resources, cache results, use hints, prefer brute force over complexity, and design for the worst case
- Fault-tolerance: Apply the end-to-end principle, use logs to record truth, and make actions atomic or restartable
The overarching themes are:
- Simplicity enables reliability: Complex systems fail in complex ways
- Plan for change: Interfaces are hard to modify, so get them right early
- Performance vs. abstraction trade-offs: Balance is an art, not a science
- Design for reliability from the start: Retrofitting it later is nearly impossible
These principles remain relevant today, even though computing has changed dramatically since 1983. The specific technologies mentioned (Alto, Dorado, ARPANET) are historical, but the underlying lessons about simplicity, performance, and reliability continue to guide modern system design.
Resources
This is #25 in my series reviewing foundational papers in Computer Science.