Immutability Changes Everything
Abstract
There is an inexorable trend towards storing and sending immutable data. We need immutability to coordinate at a distance and we can afford immutability, as storage gets cheaper. This paper is simply an amuse-bouche on the repeated patterns of computing that leverage immutability. Climbing up and down the compute stack really does yield a sense of déjà vu all over again.
What does this mean? Immutable data is data that never changes once created - like a photograph versus a whiteboard. This paper by Pat Helland explores why immutability has become a fundamental pattern throughout modern computing, from applications down to hardware.
Introduction
This is a fantastic, thought-provoking paper that reveals a surprising truth: immutability isn't just a nice-to-have feature in modern computing - it's actually what makes distributed systems and big data processing possible in the first place.
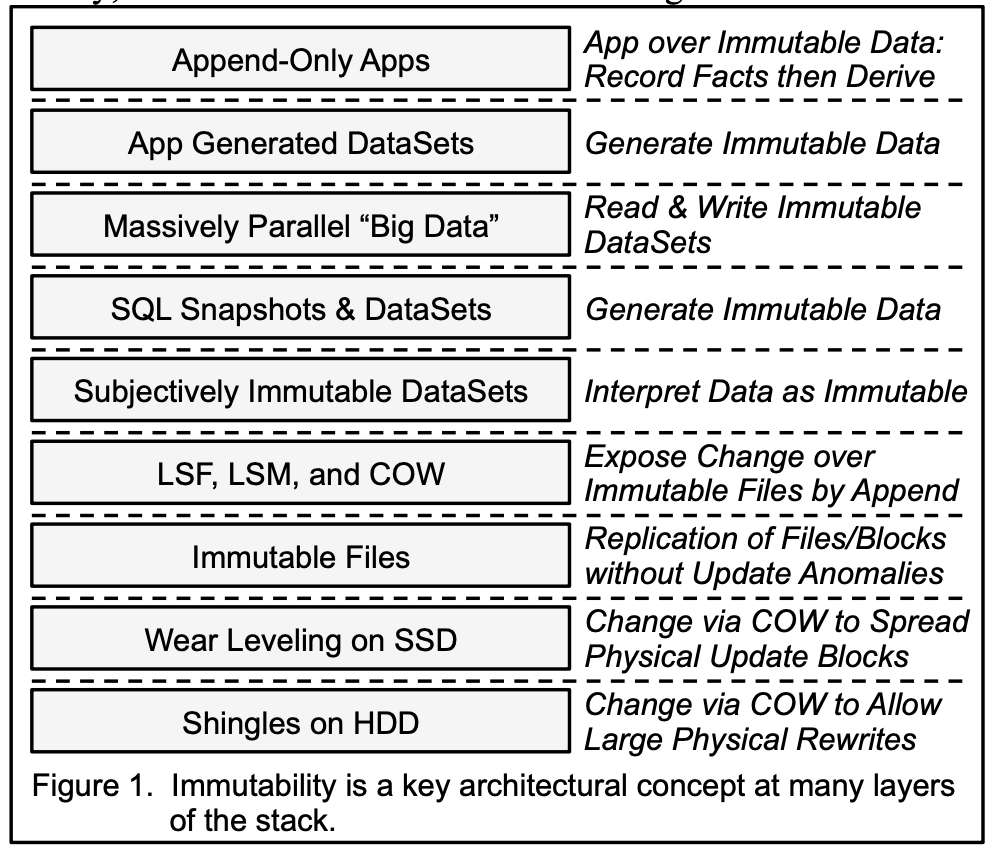
The paper takes us on a journey through the entire computing stack, showing how immutability appears at every level:
- Application level: Apps use immutability in their day-to-day operations and generate immutable datasets for later analysis
- Database level: SQL systems expose and process immutable snapshots of data
- Big Data level: Massively parallel processing frameworks rely entirely on immutable datasets
- File system level: Modern updatable systems are built on top of immutable foundations using clever techniques like LSF (Log Structured File systems), COW (Copy on Write), and LSM (Log Structured Merge trees)
- Hardware level: Even SSDs and hard drives now use immutability tricks internally
As Pat Helland says, it's "turtles all the way down" - immutability at every layer, each building on the one below.
Accountants Don't Use Erasers
This memorable section title captures a fundamental insight: in accounting ledgers, you never erase entries - you only add new ones. A mistake? Add a correction entry. This same pattern appears throughout computing.
Append-Only Computing: Many systems work by recording observations permanently and calculating results on demand. Think of it like a logbook:
- You write down what happened (observed facts)
- You write down what you figured out (derived facts)
- You never erase anything - you only add new entries
This is actually how many database systems work internally. What you see as "the database" is really just a convenient view calculated from a long history of changes stored in a log.
Ordering Matters: When multiple systems are making changes, we need a way to decide what order things happened in. This can come from:
- A single "master" system that decides the order
- A distributed consensus protocol like Paxos where multiple systems agree on the order
- Either way, changes are applied one at a time in a specific sequence
Historical Context: Before computers, paper-based workflows used carbon copies and multi-page forms - essentially creating immutable records that were distributed to different departments. Distributed computing was append-only long before we had computers!
Data on the Outside vs. Data on the Inside
This distinction is crucial for understanding how modern systems work:
Data on the Inside: This is data within your database and application code. It lives in a protected, transactional world where:
- Changes happen in a controlled, serialized way (one transaction at a time)
- You can update records in place
- The database ensures consistency through locks and transactions
- Think: rows in your SQL database that you can UPDATE
Data on the Outside: This is data that leaves your system boundaries - messages, files, documents, web pages, API responses. It has four key properties:
- Immutable: Once created, it never changes
- Unlocked: No locks needed because it can't be modified
- Has Identity: Each piece of data has a unique identifier
- Versioned: New versions are new pieces of data, not updates to old ones
Think of the difference like this: data on the inside is like a whiteboard you keep erasing and updating; data on the outside is like printed documents you file away and can always refer back to.
Referencing Immutable Data
Databases can work with immutable datasets in powerful ways:
No Locking Required: Since immutable datasets can't be changed, databases can read them without any locking mechanisms. This is huge for performance - normally databases need complex locking systems to prevent one transaction from seeing incomplete changes from another. With immutable data, you just read it. It's like the difference between trying to take a photo of a moving subject versus a still one.
Snapshots Create Immutability: Even with regular database data, snapshot isolation (a common database feature) makes the data semantically immutable for the duration of a query. Your query sees a frozen-in-time view of the data, even if other transactions are making changes. This is how databases can run complex analytical queries without interfering with ongoing updates.
Relational Operations: When databases perform JOINs and other operations on immutable datasets, they treat the data purely as values - rows and columns to be combined and transformed. They don't worry about the identity or versioning of individual records, just their content.
Immutability Is in the Eye of the Beholder
Here's a subtle but important point: immutability is about semantics (meaning), not physical storage.
Semantic vs. Physical Immutability: What matters is that a dataset appears unchanging to readers. Behind the scenes, you can:
- Add indexes to make queries faster
- Denormalize tables (duplicate data) to optimize read performance
- Partition the data and store pieces near their readers for better latency
- Convert row-oriented storage to column-oriented storage for analytics
None of these changes affect the meaning of the data, so from the reader's perspective, it's still immutable. It's like how you can print the same document on different paper sizes - the content doesn't change.
Why This Matters for Big Data: Massively parallel processing frameworks like MapReduce, Spark, and similar systems fundamentally rely on this property. They split immutable datasets across thousands of machines, process each piece independently (functional calculations), and combine the results. This only works because the input data won't change mid-computation.
No Need for Normalization: In traditional databases, normalization (organizing data to avoid redundancy) is crucial to prevent "update anomalies" - inconsistencies that can occur when you update data in one place but forget to update it elsewhere. But if your dataset is immutable, update anomalies are impossible. You can freely denormalize (duplicate data) to make reads faster without any downside.
Versions are Immutable Too!
When you need to show change over time while maintaining immutability, versioning is the answer. Each version is itself immutable.
Version History Models:
- Linear History (strong consistency): Think of Git with no branches - each version has exactly one parent and one child. One version cleanly replaces another. This is what we mean by "strongly consistent" - there's always a single, unambiguous current version.
- DAG History (Directed Acyclic Graph): Think of Git with branches - versions can have multiple parents (merges) or multiple children (branches). This allows for more flexibility but requires more complex conflict resolution.
Building Databases on Immutable Versions: Here's a powerful insight - you can build a full-featured database by storing only immutable versions:
- Each update creates a new version of the affected records
- Deletions are handled by adding "tombstones" (markers that say "this record is deleted as of version X")
- You can even build a relational database on top of a simple key-value store this way
Time Travel: Add timestamps to each version, and you get "time travel" queries for free. You can:
- View the state of the database at any point in the past
- Run queries against historical data
- Let ongoing work see a stable snapshot while other transactions make changes
LSM Trees Explained: Log Structured Merge (LSM) trees are a clever way to present a mutable interface on top of immutable storage:
- Writes create new immutable files
- Reads might need to check multiple files to find the latest version
- Background processes periodically "compact" old files into new ones
- The result: users see a regular updatable database, but underneath it's all immutable files
This is how databases like Cassandra, HBase, and RocksDB achieve high write throughput - they're just appending to immutable files.
Keeping the Stone Tablets Safe
The section title refers to immutable data as "stone tablets" - once carved, forever unchanged. How do we build reliable storage systems on this principle?
Log Structured File Systems (LFS): One of the earliest file system designs to embrace immutability:
- All writes are appended to the end of a circular buffer (think of it like a circular tape)
- Periodically, the system writes checkpoints (metadata to reconstruct the file system)
- Old data that's still needed gets copied forward before it's overwritten
- The result: extremely fast writes (just append!) and good crash recovery (just find the last checkpoint)
Distributed File Systems (GFS, HDFS): Google File System and Hadoop's file system took immutability even further:
- Each file is immutable and written by a single process
- Files are created, optionally appended to, and eventually deleted - but never modified in place
- This design makes distributed replication much simpler
- Multi-writer support is deliberately avoided because it's complex and error-prone
Why Immutability Simplifies Distributed Systems: Consider two scenarios:
- Mutable data in distributed storage: When you read a value, you might get an old version due to replication lag. Your application must handle this "eventual consistency" complexity.
- Immutable data in distributed storage: Each piece of data has only one version. You either have it or you don't - no stale reads possible!
The Distributed Systems Trade-off: Here's a fundamental limitation:
In a distributed cluster, you can know where you are writing or you can know when the write will complete but not both.
With immutable data, you know exactly where it lives because it never moves. This makes failure recovery much simpler and more predictable - you just need to re-replicate the immutable blocks from surviving nodes.
Hardware Changes towards Unchanging
Surprisingly, even hardware has adopted immutability principles - not by choice, but by necessity!
SSDs and Wear Leveling: Here's a physical constraint that forced immutability into hardware:
- Flash memory cells can only be written a finite number of times (typically 10,000 to 100,000 cycles) before they wear out
- If you kept updating the same physical location, that spot would fail quickly
- Solution: wear leveling - when you "update" a block, the SSD controller writes it to a different physical location
- The mapping from logical addresses to physical addresses is maintained by the controller
- Result: from the outside it looks like in-place updates, but internally it's all immutable writes to new locations!
This is exactly like LSM trees, but implemented in hardware. The SSD is constantly doing "garbage collection" in the background to reclaim space from old versions.
Shingled Magnetic Recording (SMR) Hard Drives: Modern high-capacity hard drives face a different constraint:
- To increase storage density, write tracks are made wider than read tracks
- Writes "shingle" over each other, overlapping like roof shingles
- This means you can't update one track without overwriting adjacent ones
- Solution: the disk controller implements a log-structured file system internally
- Writes are appended to a log, and the controller manages compaction behind the scenes
The irony: we're using immutability tricks in hardware to present a mutable interface to software, while software uses immutability tricks to present reliable systems to users!
Immutability May Have Some Dark Sides
Immutability isn't free. Here are the trade-offs you need to understand:
Storage Overhead: Since immutable data can't be updated in place, you end up with more copies:
- Denormalization: Duplicating data across a dataset to optimize reads means multiple copies of the same information
- Versioning: Keeping multiple versions of data means storing all those versions
- Storage is cheap and getting cheaper, but "cheap" isn't "free"
Write Amplification: This is a real concern in immutable systems:
- When you "update" a value, you're really writing a new version
- LSM trees might need to rewrite data multiple times during compaction (merging old files into new ones)
- SSDs face this too - a small logical update might trigger rewriting entire blocks internally
- Example: updating one row in an LSM-based database might cause that row to be rewritten during multiple compaction cycles
The Read/Write Trade-off: There's often a relationship between write amplification and read performance:
- More write amplification (more compaction, better organization) = faster reads
- Less write amplification = slower reads (need to check more files/versions)
- You tune this based on your workload: read-heavy or write-heavy?
Despite these downsides, the benefits (simpler distributed systems, better parallelism, no locking) often outweigh the costs.
Conclusion
Immutability does change everything!
Pat Helland's paper reveals that immutability isn't just a programming technique - it's a fundamental architectural pattern that appears throughout the computing stack:
- Application layer: Append-only logs and event sourcing
- Database layer: Snapshots, versioning, and LSM trees
- Big Data layer: MapReduce and parallel processing frameworks
- File system layer: Log-structured file systems
- Hardware layer: SSD wear leveling and shingled hard drives
The pattern repeats at every level because immutability solves fundamental problems:
- Coordination: Immutable data can be safely shared without locks or complex synchronization
- Distribution: Immutable data can be replicated without worrying about consistency
- Parallelism: Immutable data can be processed by thousands of machines simultaneously
- Time travel: Immutable versions give you the history of changes for free
As storage becomes cheaper and distributed systems become the norm, immutability has shifted from "nice to have" to "essential foundation." Understanding this pattern helps you see why modern systems are designed the way they are - from the databases you use daily to the hardware they run on.
Over the next few Saturdays, I'll be going through some of the foundational papers in Computer Science, and publishing my notes here. This is #12 in this series.