Kafka: a Distributed Messaging System for Log Processing
What is Kafka?
Kafka is a distributed messaging system developed by LinkedIn to handle massive amounts of data in real-time. Think of it as a highly scalable postal service for data: producers send messages, Kafka stores and organizes them, and consumers retrieve them at their own pace.
The Problem Kafka Solves
Large internet companies generate enormous amounts of log data every day—things like user clicks, page views, logins, and system metrics. Traditional messaging systems couldn't handle this volume efficiently. Kafka was built specifically to:
- Handle high throughput: Process hundreds of thousands of messages per second
- Provide low latency: Deliver data in near real-time (milliseconds, not seconds)
- Scale horizontally: Add more machines to increase capacity
- Support diverse use cases: Work for both real-time analytics and batch processing
Paper Abstract
Log processing has become a critical component of the data pipeline for consumer internet companies. We introduce Kafka, a distributed messaging system that we developed for collecting and delivering high volumes of log data with low latency. Our system incorporates ideas from existing log aggregators and messaging systems, and is suitable for both offline and online message consumption. We made quite a few unconventional yet practical design choices in Kafka to make our system efficient and scalable. Our experimental results show that Kafka has superior performance when compared to two popular messaging systems. We have been using Kafka in production for some time and it is processing hundreds of gigabytes of new data each day.
Key Design Decisions
Why These Choices Matter
Kafka's designers made several deliberate trade-offs to optimize for their specific use case: processing massive volumes of log data. Here's what they prioritized:
1. Support Both Real-Time and Batch Processing
Large internet companies generate enormous amounts of log data:
- User activity data: Logins, page views, clicks, likes, searches
- Operational metrics: Server performance, error rates, response times
This data needs to serve two purposes:
- Real-time (online): Power live features like recommendations, fraud detection, and personalized content
- Batch processing (offline): Feed into data warehouses for analytics and machine learning
Kafka handles both use cases with the same infrastructure.
2. Pull Model (Consumers Control the Flow)
Unlike traditional messaging systems where the broker pushes messages to consumers, Kafka uses a pull model where consumers request messages from the broker.
Why pull over push?
- Consumers control their pace: Each consumer retrieves messages as fast as it can process them, preventing overload
- Easy to replay messages: Consumers can "rewind" and reprocess old data if needed (great for debugging or reprocessing after fixing a bug)
- Simpler broker design: The broker doesn't need to track which consumers are overwhelmed
The trade-off: Consumers must poll for new data, which could waste resources if no new messages are available. Kafka mitigates this with long-polling (the consumer waits at the broker until new messages arrive).
3. At-Least-Once Delivery (Not Exactly-Once)
Kafka guarantees at-least-once delivery, meaning a message might be delivered more than once but will never be lost.
Why this trade-off?
- Simpler and faster: Guaranteeing exactly-once delivery is complex and slow (requires two-phase commits)
- Good enough for logs: For log data like page views, processing a message twice is acceptable—losing it completely is worse
- Let applications decide: If an application needs deduplication, it can implement it using message offsets (position in the log) or unique message IDs
This pragmatic approach prioritizes performance over perfect guarantees.
4. Ordered Delivery Within Partitions Only
Kafka guarantees that messages within a single partition are delivered in order, but provides no ordering guarantees across different partitions.
Why?
- Enables parallelism: Different partitions can be processed independently and concurrently
- Scales better: Adding more partitions increases throughput
- Sufficient for most use cases: Applications that need ordering can use a partitioning key to ensure related messages go to the same partition
How Kafka Works: Architecture Explained
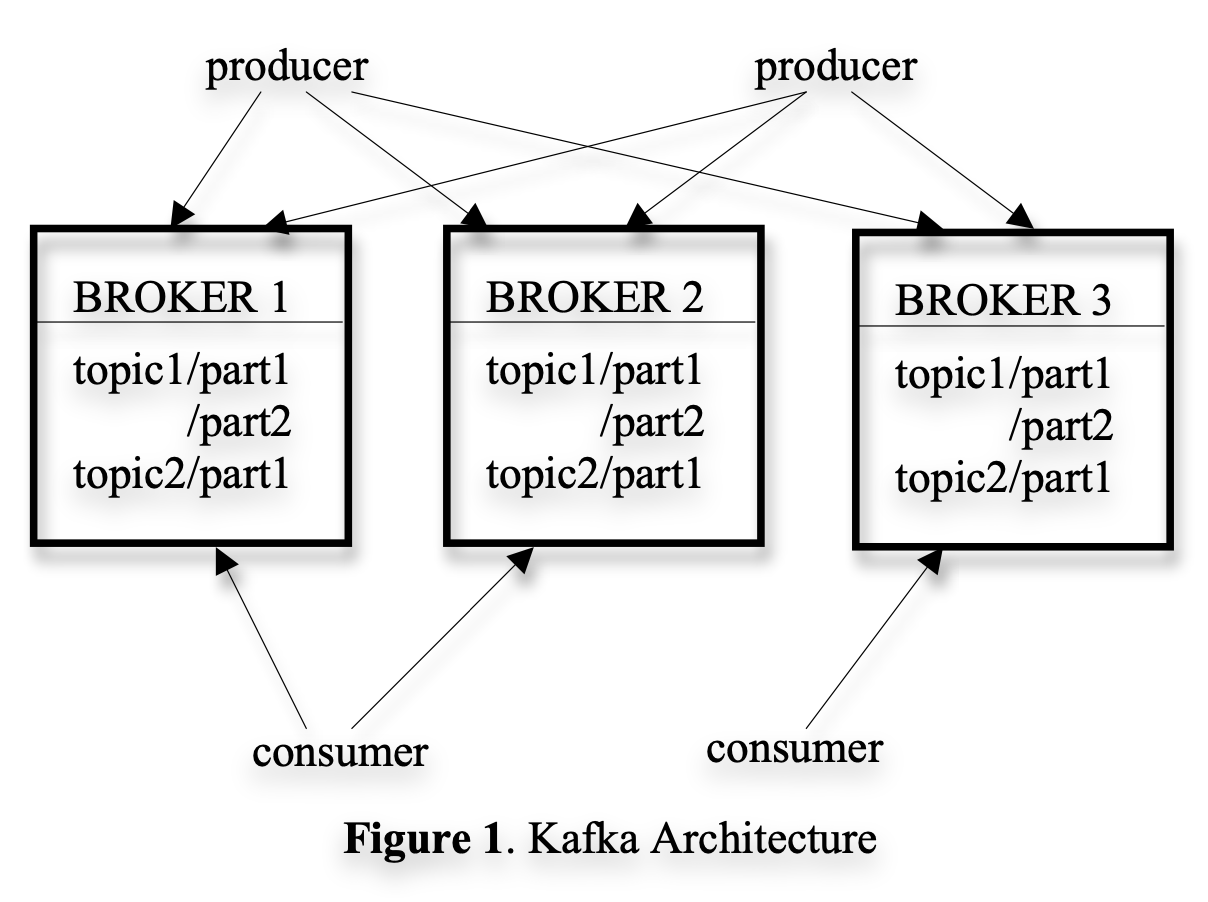
Let's break down the core components and how they work together:
Core Concepts
Topics and Partitions
- Topic: A category or stream of messages (like "user-clicks" or "server-logs"). Think of it as a folder that organizes related messages.
- Partition: Topics are split into partitions for parallelism and scalability. Each partition is an ordered, immutable sequence of messages.
Example: A "user-clicks" topic might have 10 partitions, allowing 10 consumers to process clicks in parallel.
Producers
Producers are applications that publish messages to Kafka topics. When sending a message, a producer can:
- Let Kafka choose a partition randomly (for load balancing)
- Specify a partitioning key (e.g., user ID) so related messages always go to the same partition
Brokers
Brokers are the Kafka servers that store and serve data. Key characteristics:
- Each broker stores one or more partitions
- A partition is stored as a log—an append-only sequence of messages
- Physically, each log consists of multiple segment files (typically ~1GB each)
- Brokers keep an in-memory index of offsets (the position of messages in the log) for fast lookups
Performance optimization: Kafka doesn't immediately flush every message to disk. Instead, it:
- Batches messages in memory
- Flushes to disk after a configurable number of messages or time interval
- Only exposes messages to consumers after they're flushed (ensuring durability)
This batching dramatically improves throughput.
Consumers
Consumers subscribe to topics and pull messages from brokers. Important details:
- While the consumer API processes one message at a time, each pull request actually fetches hundreds of kilobytes of messages (batching for efficiency)
- Multiple consumers can form a consumer group to share the workload (each partition is consumed by only one consumer in the group)
Coordination with Zookeeper
Kafka uses Zookeeper for distributed coordination—there's no central "master" broker. Zookeeper provides:
- Service discovery: Where are the brokers? Which broker owns which partition?
- Configuration management: Storing and distributing cluster configuration
- Leader election: Choosing which broker leads for a given partition
- Consumer coordination: Tracking which consumers are alive and which partitions they're consuming
Zookeeper's key features:
- File-system-like API: Create paths, set values, read values, list children
- Watchers: Get notified when data changes (e.g., when a broker dies)
- Ephemeral nodes: Temporary paths that disappear when the client disconnects (used for detecting failures)
- Replication: Data is replicated across multiple Zookeeper servers for high availability
Note: Modern Kafka (2.8+) is moving away from Zookeeper dependency, but the original paper used Zookeeper extensively.
Kafka's Clever Optimizations
Kafka's exceptional performance comes from several unconventional design choices that challenge traditional messaging system assumptions:
1. Offsets Instead of Message IDs
Traditional approach: Each message gets a unique ID, requiring an index to map IDs to storage locations.
Kafka's approach: Messages are identified by their offset (position) in the log. The offset is simply a number that increases as messages are appended.
Benefits:
- No need for complex indexing structures
- Sequential disk access (very fast)
- Simple arithmetic: next message offset = current offset + current message length
Trade-off: Offsets are increasing but not consecutive (they depend on message size).
2. Never-Ending Iterators
When a consumer reads messages, the iterator doesn't stop when it reaches the end of available data—it blocks and waits for new messages.
This is perfect for real-time stream processing where new data is constantly arriving.
3. Flexible Messaging Models
Kafka supports both major messaging patterns:
- Point-to-point (queue): Multiple consumers in a group share the workload, each processing different partitions
- Publish-subscribe: Multiple consumer groups each get their own complete copy of all messages
This flexibility allows the same Kafka cluster to serve diverse use cases simultaneously.
4. Zero-Copy with sendfile()
The problem: Traditionally, sending data from disk to network involves multiple copies:
- Disk → Kernel buffer
- Kernel buffer → Application memory
- Application memory → Socket buffer
- Socket buffer → Network card
Kafka's solution: Use the Linux sendfile() system call to transfer data directly from the file to the network socket, bypassing application memory entirely.
Impact: Dramatically reduces CPU usage and latency when serving messages to consumers.
5. Rely on Operating System Page Cache
Traditional approach: Messaging systems maintain their own in-memory cache of messages.
Kafka's approach: Let the operating system's page cache handle caching. Modern OSes are excellent at caching frequently accessed files.
Benefits:
- Simpler code (no cache management logic)
- Better memory utilization (OS makes intelligent caching decisions)
- Cache survives process restarts
- No garbage collection pressure (especially important for JVM-based systems)
6. Stateless Brokers
Traditional approach: Brokers track which messages each consumer has processed.
Kafka's approach: Consumers track their own position (offset) in the log.
Benefits:
- Simpler broker design
- Consumers can rewind and reprocess data
- Easy to add new consumers
The deletion challenge: If brokers don't know what consumers have read, when can messages be deleted?
Solution: Time-based retention policy. Messages are kept for a configurable time period (e.g., 7 days), regardless of whether they've been consumed. This simple approach works well for log data and simplifies the system design.
7. Easy Data Replay
Because consumers track their own offsets, they can deliberately "rewind" to an earlier point and reprocess old messages.
Use cases:
- Recovering from bugs (fix the bug, then reprocess)
- Backfilling data for new consumers
- Testing with production data
- A/B testing different processing algorithms
Performance Results
The paper compared Kafka against two popular messaging systems: ActiveMQ and RabbitMQ.
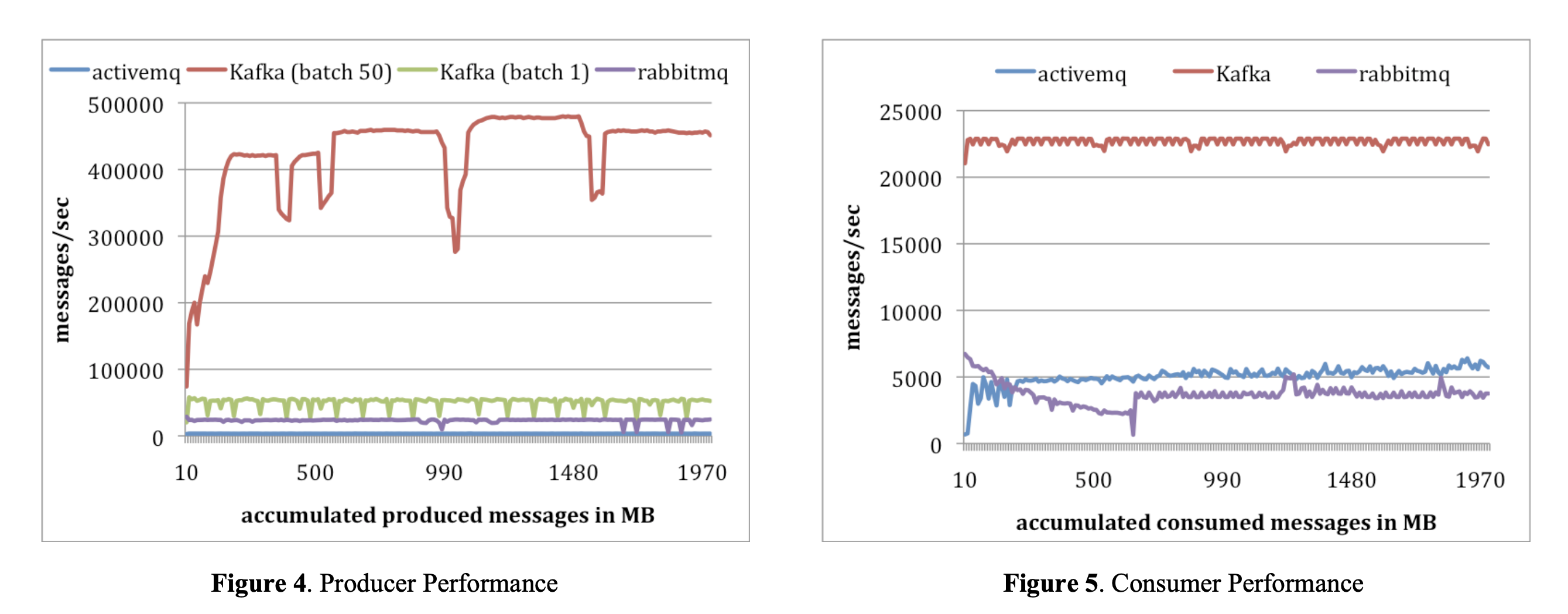
Producer Throughput
Kafka's batching strategy shows dramatic performance improvements:
- Batch size = 1 (send each message individually): 50,000 messages/second
- Batch size = 50 (send 50 messages at once): 400,000 messages/second
Key insight: Batching provides an 8x performance improvement by amortizing network and I/O overhead across multiple messages.
Consumer Throughput
Kafka significantly outperformed the competition:
- Kafka: 22,000 messages/second
- ActiveMQ & RabbitMQ: ~5,000 messages/second
Kafka's advantage: 4x faster than traditional messaging systems, thanks to sequential I/O, zero-copy transfers, and OS page cache optimization.
Real-World Scale
At the time of publication, Kafka was processing hundreds of gigabytes of new data each day at LinkedIn, demonstrating its production readiness for internet-scale workloads.
Future Directions
The paper identified several areas for improvement (many of which have since been implemented in modern Kafka):
1. Built-in Replication
Add replication across multiple brokers to ensure messages aren't lost if a machine fails.
Status in modern Kafka: Implemented! Kafka now has robust replication with configurable replication factors.
2. Stream Processing
Add native stream processing capabilities directly in Kafka.
Status in modern Kafka: Kafka Streams API now provides powerful stream processing without needing external frameworks.
3. Stream Utilities
Provide a library of common stream operations like windowing (grouping messages by time) and joins (combining multiple streams).
Status in modern Kafka: Kafka Streams includes rich support for windowing, joins, aggregations, and more.
Putting Scale in Perspective
To understand the magnitude of log data at internet companies (as of 2011):
- China Mobile: Collects 5-8 TB of phone call records daily
- Facebook: Gathers ~6 TB of user activity events daily
These numbers would be much larger today, but they illustrate why traditional messaging systems couldn't handle the load—and why Kafka was necessary.
Key Takeaways
Kafka succeeded by making pragmatic design choices tailored to its specific use case (log processing):
- Pull-based consumption: Let consumers control their pace
- At-least-once delivery: Good enough for logs, much faster than exactly-once
- Simple storage model: Append-only logs with offset-based addressing
- Leverage the OS: Use page cache and zero-copy transfers
- Stateless brokers: Push complexity to consumers for simpler, more scalable brokers
- Time-based retention: Simple deletion policy that works well for log data
These unconventional choices enabled Kafka to achieve 4x better performance than competing systems while handling internet-scale workloads.
Resources
This is #2 in my paper review series, where I explore foundational papers in Computer Science.