MapReduce: Simplified Data Processing on Large Clusters
What Problem Does MapReduce Solve?
Imagine you work at Google in the early 2000s, and you need to process massive amounts of web data—think terabytes of information across millions of web pages. You want to count how many times each word appears across the entire web, or find all the links pointing to each website.
The challenge isn't just writing the logic for these tasks (which is actually straightforward), but rather: How do you split this work across hundreds or thousands of computers? What happens when one of those computers crashes? How do you combine all the results back together?
This is where MapReduce comes in. It's a framework developed by Google engineers Jeffrey Dean and Sanjay Ghemawat that lets you write simple programs to process massive datasets without worrying about all the distributed computing complexities.
The Key Insight
MapReduce makes a brilliant observation: most large-scale data processing tasks can be broken down into two simple operations:
- Map: Transform each piece of input data into intermediate key-value pairs
- Reduce: Combine all the intermediate values that share the same key
The beauty is that once you write these two simple functions, MapReduce automatically handles:
- Splitting your work across thousands of machines (parallelization)
- Moving data between machines efficiently
- Recovering from machine failures
- Combining all the results
In other words, you write simple code as if you're processing data on a single machine, and MapReduce makes it run efficiently on thousands of machines.
How MapReduce Works: A Concrete Example
Let's use a simple example to understand MapReduce: counting how many times each word appears in a collection of documents.
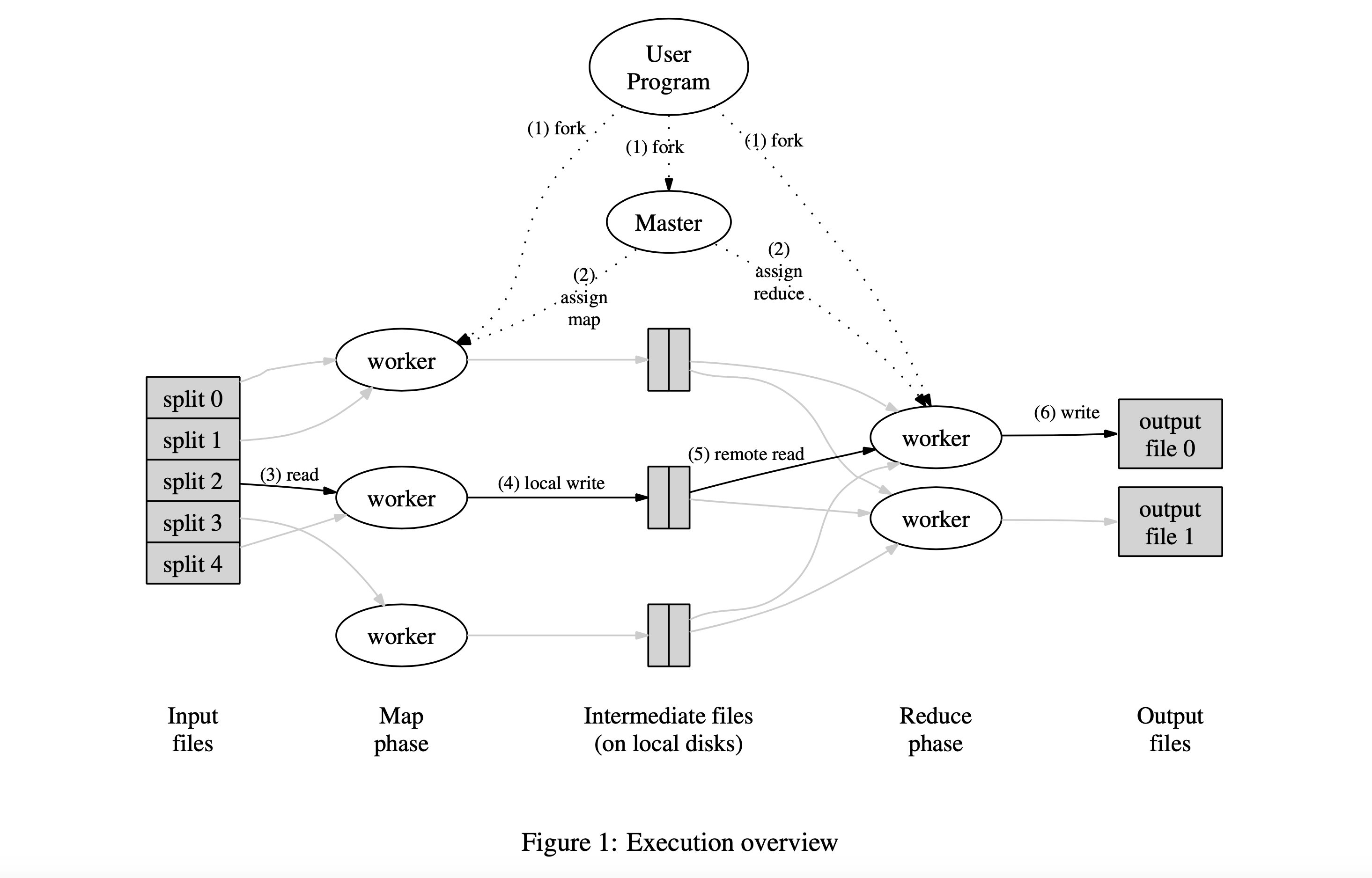
The Map Function
The Map function processes each document and outputs intermediate key-value pairs. For word counting:
- Input: A document (e.g., "Hello world, hello MapReduce")
- Output: A list of word-count pairs:
[("hello", 1), ("world", 1), ("hello", 1), ("mapreduce", 1)]
Each Map worker processes different documents in parallel, all generating these intermediate pairs.
The Shuffle Phase (Handled Automatically)
MapReduce groups all intermediate values by their key. So all the "hello" pairs go together, all the "world" pairs go together, etc. This grouping happens automatically—you don't write code for this.
The Reduce Function
The Reduce function receives a key and all the values associated with that key. For word counting:
- Input: A key and its values (e.g., "hello" and
[1, 1, 1]) - Output: The sum (e.g., "hello", 3)
Type Signatures
If you're familiar with functional programming, here's the type signature:
map (k1, v1) → list(k2, v2)
reduce (k2, list(v2)) → list(v2)
This means Map takes one key-value pair and produces a list of intermediate pairs. Reduce takes a key and a list of values, and produces a list of output values (often just one).
Handling Large Data
A clever design choice: the intermediate values are passed to your Reduce function via an iterator rather than a full list. This means you can process datasets larger than your machine's memory—you just process the values one at a time rather than loading them all at once.
Real-World Applications
This simple model is surprisingly powerful. Here are some problems you can solve with MapReduce:
- Distributed Grep: Search for a pattern across millions of files
- URL Access Frequency: Count how often each URL is accessed in web logs
- Reverse Web-Link Graph: Find all pages that link to each URL
- Inverted Index: Build a search engine index (map words to documents)
- Distributed Sort: Sort massive datasets across multiple machines
Key Design Decisions
Now that you understand the basic model, let's look at how Google made MapReduce work reliably at massive scale. These design choices are what make MapReduce practical for real-world use.
1. Fault Tolerance: Handling Failures Gracefully
When you're running computations on thousands of machines, failures are not exceptional—they're expected. Machines crash, networks fail, disks die. MapReduce is designed to handle this:
Worker Failure (the common case):
- When a worker machine fails, any completed Map tasks on that machine must be re-run, even if they finished successfully. Why? Because Map output is stored on the worker's local disk, which is now inaccessible.
- However, completed Reduce tasks don't need to be re-run because their output is stored in a global file system (like Google File System) that's accessible from anywhere.
Master Failure (the rare case):
- The master is the coordinator that manages all the workers. Since there's only one master, the system periodically saves checkpoints of the master's state.
- If the master fails, you could restart it from the last checkpoint. However, since master failures are rare, Google's implementation simply aborts the entire MapReduce job and lets the user restart it. This keeps the design simpler.
Non-deterministic Functions:
- If your Map or Reduce functions produce different outputs on different runs (maybe they use random numbers), MapReduce provides the same guarantees as running your program sequentially. Each Reduce task's output will be consistent with some sequential execution of your program.
2. Locality: Moving Computation to Data
When processing terabytes of data, network bandwidth becomes a bottleneck. It's much faster to move your computation to where the data lives than to move the data across the network.
MapReduce leverages this by being smart about task scheduling:
- The master knows where each piece of input data is stored (typically in Google File System, which replicates data across multiple machines)
- When scheduling a Map task, it tries to run it on a machine that already has a copy of the input data
- If that's not possible, it schedules the task on a machine in the same network rack (close to the data)
This simple optimization dramatically reduces network traffic and speeds up execution.
3. Task Granularity: How Many Tasks Should You Create?
You might wonder: if you have 1,000 worker machines, should you create exactly 1,000 Map tasks? The answer is no—you should create many more!
Why create more tasks than workers?
- Better load balancing: Some tasks finish faster than others. If you have more tasks than workers, faster workers can pick up extra tasks instead of sitting idle.
- Faster failure recovery: If a worker fails, its tasks can be redistributed across all other workers instead of overwhelming a single replacement worker.
But don't go overboard:
- The master needs to make scheduling decisions for all tasks, which takes time and memory: O(M + R) scheduling decisions and O(M × R) state.
- Each Reduce task produces one output file, so too many Reduce tasks means too many output files, which can be inconvenient.
Google's practical guidelines:
- Choose M (number of Map tasks) so each task processes 16-64 MB of input data. This keeps tasks small enough for good parallelism while making the locality optimization effective.
- Make R (number of Reduce tasks) a small multiple of the number of workers you'll use.
- Example from Google: A typical job might use M = 200,000 Map tasks and R = 5,000 Reduce tasks running on 2,000 worker machines.
4. Backup Tasks: Dealing with Stragglers
Here's a frustrating scenario: your MapReduce job is 99% complete, but one slow machine is taking forever to finish its last task. Everyone's waiting on that one straggler.
What's a "straggler"? A machine that takes unusually long to complete one of the last few tasks. This might happen because:
- The machine has a failing disk (slow reads)
- It's competing with other jobs for resources
- It has a bad configuration
Google's solution: When a MapReduce job is close to completion, the master schedules backup executions of any remaining in-progress tasks. The task is marked complete as soon as either the primary or backup execution finishes—whichever comes first.
This clever trick uses only a few percent more computational resources but can dramatically speed up job completion. Without backup tasks, stragglers could extend job runtime by significant amounts.
5. Combiner Function: Reducing Network Traffic
Remember our word count example? Each Map worker might emit thousands of pairs like ("the", 1), ("the", 1), ("the", 1)... before sending them over the network.
The problem: Sending all these intermediate pairs over the network is wasteful.
The solution: An optional Combiner function that does local aggregation before sending data across the network. For word count, instead of sending ("the", 1) a thousand times, the Combiner can locally sum them up and send ("the", 1000) once.
Key insight: Often, you can use the same code for both your Combiner and Reduce functions. In word count, both just sum up values. The only difference is where they run:
- Combiner runs on the Map worker, on a subset of intermediate data
- Reduce runs on the Reduce worker, on all data for a key
This optimization can significantly reduce network bandwidth and speed up jobs.
6. Flexible Input Types
MapReduce doesn't force you to read data from files. The system provides a simple reader interface that you can implement to read data from anywhere:
- Text files (the most common case)
- Databases
- In-memory data structures
- Network streams
- Any custom data source
This flexibility means you can use MapReduce for a wide variety of data processing tasks without having to first export all your data to files.
7. Handling Side Effects
Sometimes you need your Map or Reduce functions to produce additional output files beyond the standard MapReduce output (called "side effects").
Important considerations:
- Make side effects atomic: Write to a temporary file, then atomically rename it when complete. This prevents other processes from reading partial data.
- Make side effects idempotent: If a task runs twice (due to failures and retries), it should produce the same result. This prevents duplicate or corrupted data.
Limitations:
- MapReduce doesn't support atomic commits across multiple output files from a single task. If you need this, your tasks should be deterministic so that re-running them produces identical output.
8. Skipping Bad Records
Imagine processing billions of records, and one corrupted record keeps crashing your Map function. Without special handling, that single bad record would cause your entire job to fail.
MapReduce's solution: An optional mode where the system automatically detects and skips problematic records:
- If a record causes a crash, MapReduce retries processing it
- If the same record causes crashes multiple times (deterministic crashes), the master marks it as "bad"
- On subsequent retries, that record is skipped
This allows you to make forward progress even when processing messy, real-world data with occasional corrupted records. You can review the skipped records later to understand what went wrong.
9. Local Execution Mode for Debugging
Debugging distributed systems is notoriously difficult. How do you debug code that runs across thousands of machines?
MapReduce's answer: A local execution mode where you can run your MapReduce job on a single machine, processing only specific tasks. This lets you:
- Use familiar debugging tools like
gdb - Set breakpoints and inspect variables
- Run on a small subset of data
- Iterate quickly without waiting for cluster scheduling
You simply run your program with a special flag to enable local mode, test and debug your logic, then run it at full scale on the cluster.
10. Status Dashboard
When you're running jobs across thousands of machines, you need visibility into what's happening. The master runs an internal HTTP server that provides web-based status pages showing:
- How many tasks are completed, in-progress, or failed
- Which workers are processing which tasks
- Progress metrics and estimated completion time
- Resource usage statistics
This real-time dashboard helps you monitor and troubleshoot your MapReduce jobs.
11. Built-in Counters
MapReduce provides a simple but powerful counter system for tracking metrics during job execution. You can create custom counters in your code to track things like:
- Total number of words processed
- Number of malformed records encountered
- Number of German documents indexed
- Any application-specific metrics
How it works:
- Each worker maintains counters locally
- Counter values are periodically sent to the master (along with regular heartbeat messages)
- The master aggregates counters from all workers
- You can view the final counter values when the job completes
Automatic counters: MapReduce also maintains built-in counters like:
- Total input key-value pairs processed
- Total output key-value pairs produced
- Number of bytes read and written
This is incredibly useful for understanding your data and debugging issues at scale.
Real-World Impact at Google
By the time this paper was published in 2004, MapReduce had become fundamental infrastructure at Google. Here's how it was being used:
Machine Learning: Training large-scale machine learning models on massive datasets
Product Features:
- Clustering and categorization for Google News and Froogle (Google's shopping search)
- Powering Google Zeitgeist (reports on popular search queries)
- Extracting geographical locations from web pages to improve local search results
Infrastructure:
- Building search engine indexes (inverted index construction)
- Large-scale graph computations (like PageRank for web search)
- Processing web crawl data
Why was it so successful? The key insight from Google's experience: MapReduce made it possible to write a simple program and run it efficiently on a thousand machines in about half an hour. This dramatically accelerated the development cycle. Instead of spending weeks building and debugging distributed systems, engineers could focus on their actual problem and prototype solutions quickly.
At Google, over 1,000 MapReduce jobs were running every day by the time this paper was published. This shows how the abstraction resonated with engineers—it solved a real problem in an elegant way.
Key Takeaways
The MapReduce paper demonstrates three fundamental achievements:
1. Simplicity through Abstraction MapReduce made distributed computing accessible to every engineer at Google, not just distributed systems experts. By hiding the complexity of parallelization, fault tolerance, data distribution, and load balancing behind a simple Map-Reduce interface, it democratized large-scale data processing.
2. Broad Applicability A surprisingly large variety of real-world problems can be expressed as MapReduce computations. From web indexing to machine learning to log analysis—the programming model proved flexible enough for diverse use cases.
3. Proven Scalability Google successfully implemented MapReduce to scale to clusters of thousands of commodity machines processing terabytes of data. The system handled the messy realities of large-scale computing: machine failures, network issues, slow machines (stragglers), and uneven workload distribution.
Historical Context and Legacy
This 2004 paper was hugely influential in the tech industry. It inspired:
- Hadoop: An open-source implementation that brought MapReduce to the wider world
- Apache Spark: A successor that improved on MapReduce's limitations
- Modern data processing frameworks: Many current systems trace their lineage to ideas in this paper
While newer frameworks have largely superseded MapReduce at scale, the core insight remains valuable: complex distributed systems can be made accessible through the right abstractions.
Further Reading
Original Paper:
- MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat (OSDI 2004)
- My annotated copy with additional notes
If you're interested in learning more:
- The paper itself is very readable and includes detailed performance measurements
- Look into Hadoop if you want to experiment with MapReduce yourself
- Study Apache Spark to see how the industry evolved beyond MapReduce
This is #3 in my series of foundational papers in Computer Science. I'm reading and summarizing classic papers to understand the ideas that shaped modern computing.