Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center
What Problem Does Mesos Solve?
Imagine you have a data center with hundreds or thousands of computers (called a cluster), and you want to run different types of data processing jobs on them. Some jobs might use Hadoop (good for batch processing), others might use MPI (good for scientific computing), and so on. How do you efficiently share these computers among all these different frameworks without wasting resources?
This is the problem Mesos solves.
Abstract
We present Mesos, a platform for sharing commodity clusters between multiple diverse cluster computing frameworks, such as Hadoop and MPI. Sharing improves cluster utilization and avoids per-framework data replication. Mesos shares resources in a fine-grained manner, allowing frameworks to achieve data locality by taking turns reading data stored on each machine. To support the sophisticated schedulers of today's frameworks, Mesos introduces a distributed two-level scheduling mechanism called resource offers. Mesos decides how many resources to offer each framework, while frameworks decide which resources to accept and which computations to run on them. Our results show that Mesos can achieve near-optimal data locality when sharing the cluster among diverse frameworks, can scale to 50,000 (emulated) nodes, and is resilient to failures.
In simpler terms: Mesos is like an operating system for your data center. Just as your laptop's OS lets different applications (browser, music player, code editor) share your CPU and memory, Mesos lets different data processing frameworks share the computers in a data center efficiently.
Introduction
Why Do We Need Mesos?
Organizations want to run multiple frameworks in the same cluster, picking the best tool for each job. For example, you might use:
- Hadoop for batch processing large datasets (like MapReduce jobs)
- MPI (Message Passing Interface) for scientific computing that requires tightly coordinated parallel processing
- Spark for iterative machine learning workloads
Sharing a cluster between frameworks improves utilization and allows applications to share access to large datasets that would be too expensive to copy across separate clusters.
What's Wrong with Existing Solutions?
Before Mesos, there were two common approaches to sharing a cluster:
- Static partitioning: Divide the cluster into fixed sections and dedicate each section to one framework. For example, give Hadoop nodes 1-50, MPI nodes 51-100, etc.
- VM allocation: Allocate a set of virtual machines to each framework.
Both approaches have serious limitations:
- They achieve poor utilization (if one framework isn't using its allocated resources, they sit idle)
- They make data sharing inefficient (data needs to be replicated across partitions)
- They don't support fine-grained sharing (you can't quickly reallocate resources based on changing needs)
The Mesos Solution
The authors propose Mesos, a thin resource sharing layer that enables fine-grained sharing across diverse cluster computing frameworks by giving them a common interface for accessing cluster resources. Think of it as a "resource broker" that sits between the physical hardware and the frameworks.
Why Is This Problem Hard?
Designing a system that can efficiently share resources across many different frameworks is challenging for several reasons:
-
Different frameworks have different needs: Hadoop needs to place tasks near the data to minimize network traffic (data locality). MPI needs to allocate a fixed set of machines all at once. Each framework has unique scheduling requirements based on its programming model, communication patterns, and task dependencies.
-
Scale: The system must handle clusters with tens of thousands of computers running hundreds of jobs with millions of individual tasks.
-
Reliability: Since all applications depend on Mesos, it must be fault-tolerant and highly available. Any downtime affects everyone.
Why Not Use a Centralized Scheduler?
You might think the solution is to build one smart, centralized scheduler that understands all frameworks' requirements and makes all scheduling decisions. But this approach has problems:
-
Complexity: A centralized scheduler that understands every framework's needs would be extremely complex to design and maintain.
-
Unknown requirements: New frameworks and scheduling policies are constantly being developed. We don't have a complete specification of what all frameworks need now, let alone in the future.
-
Refactoring costs: Many existing frameworks already implement sophisticated scheduling logic. Moving this to a central scheduler would require expensive rewrites.
The Key Innovation: Resource Offers
Instead, Mesos takes a different approach: it delegates scheduling control to the frameworks themselves. This is accomplished through a new abstraction called resource offers.
Here's how it works:
- A resource offer is simply a bundle of available resources (e.g., "4 CPU cores and 8GB RAM on machine X")
- Mesos decides how many resources to offer each framework (based on fair sharing or other policies)
- Frameworks decide which offers to accept and which tasks to run on them
This design is simple and efficient to implement, allowing Mesos to be highly scalable and robust to failures. It's a clever division of responsibility: Mesos handles fair allocation, while frameworks handle their own complex scheduling logic.
Additional Benefits
Beyond efficient resource sharing, Mesos provides several practical benefits:
- Multiple versions: Run multiple instances or versions of the same framework in one cluster. This is great for testing new versions alongside production workloads.
- Isolation: Keep production and experimental workloads separate, reducing risk when trying new things.
- Easy experimentation: Quickly try out new frameworks without dedicated hardware or complex setup.
Implementation Highlights
- Implemented in just 10,000 lines of C++ (remarkably compact for such a powerful system)
- Scales to 50,000 emulated nodes
- Uses ZooKeeper for fault tolerance (ZooKeeper is a coordination service that helps manage distributed systems)
Bonus: The Spark Framework
To demonstrate Mesos's value, the authors built a new framework called Spark. It's optimized for iterative jobs where the same dataset is reused across many operations (common in machine learning). By caching data in memory across iterations, Spark outperforms Hadoop by 10x on iterative machine learning workloads. Building Spark on Mesos took only 1,300 lines of code because Mesos handled all the infrastructure complexity.
Target Environment
Mesos was designed with real-world data center workloads in mind. Here's what's typical:
Workload Characteristics
- Short jobs: Most jobs are quick (median: 84 seconds)
- Fine-grained tasks: Jobs consist of many small tasks (median: 23 seconds per task)
- Interactive queries: Think 1-2 minute ad-hoc SQL queries through tools like Hive
This fine-grained nature is actually perfect for Mesos. When tasks finish quickly, resources become available frequently, allowing Mesos to reallocate them to other frameworks.
Real-World Example: Facebook
Facebook uses a fair scheduler for Hadoop that allocates resources at the task level and optimizes for data locality (running tasks on machines that already have the data). This works great for Hadoop, but the problem is: the cluster can only run Hadoop jobs. Mesos solves this by enabling the same fine-grained scheduling across multiple different frameworks.
Architecture
Design Philosophy
By pushing scheduling control to the frameworks (rather than centralizing it), Mesos achieves two important goals:
- Flexibility: Frameworks can implement diverse approaches to scheduling and resource management based on their unique needs.
- Simplicity: Mesos itself stays simple and changes infrequently, making it easier to keep scalable and robust.
The authors expect higher-level libraries for common functionality (like fault tolerance) to be built on top of Mesos, creating a rich ecosystem.
Components
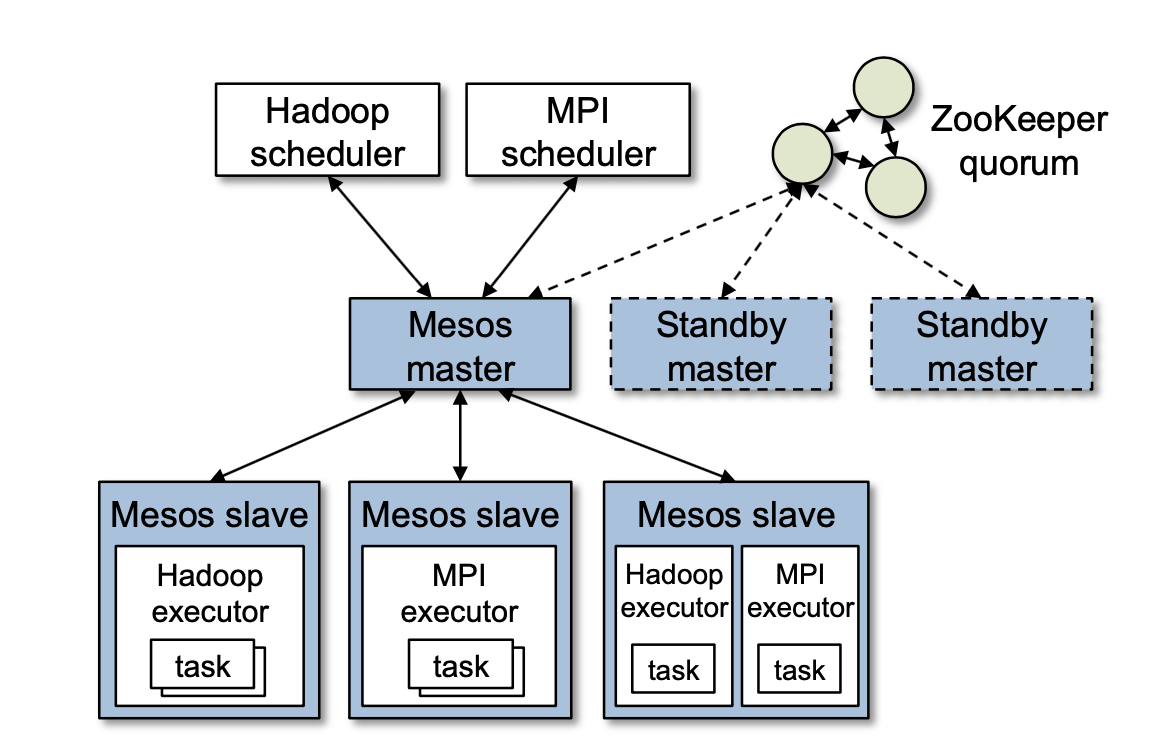
Mesos has a straightforward architecture with three main parts:
- Mesos Master: A central process that manages the cluster and makes resource offers
- Mesos Slaves: Daemons running on each cluster node that report available resources
- Frameworks: Applications (like Hadoop or MPI) that run on Mesos
Framework Structure
Each framework has two components:
- Scheduler: Registers with the master to receive resource offers and decides which offers to accept
- Executor: Launched on slave nodes to actually run the framework's tasks
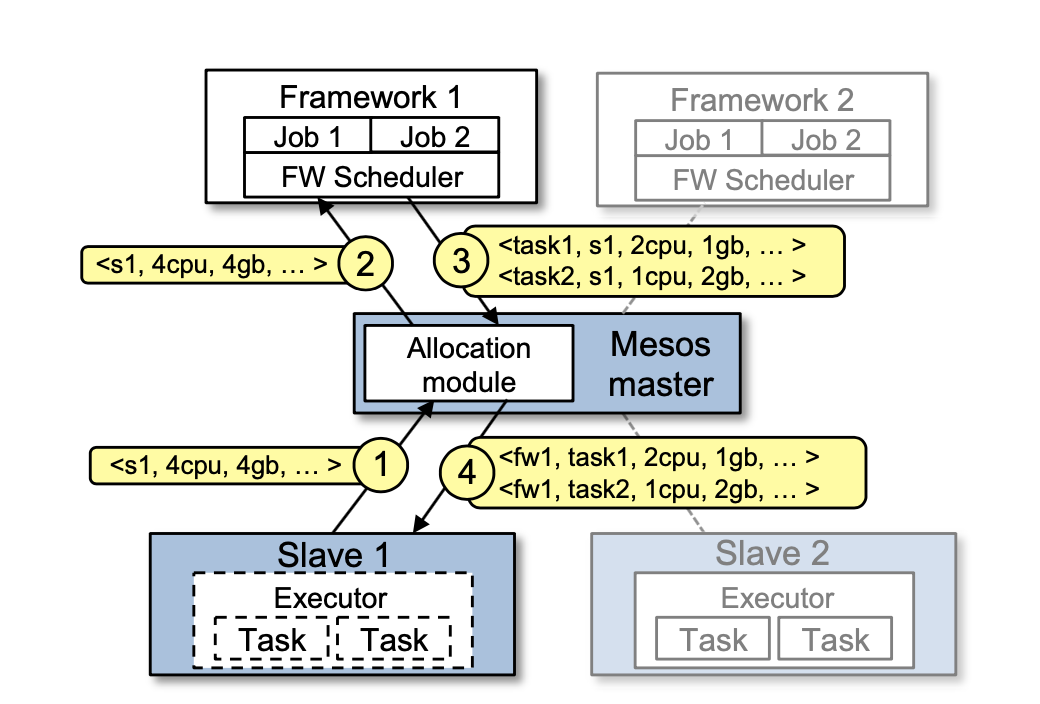
How It Works
- Slaves report their available resources to the master
- The master makes resource offers to frameworks (e.g., "4 CPUs and 8GB RAM on node 5")
- Framework schedulers decide whether to accept or reject each offer
- Accepted resources are used to launch tasks via executors
Customization
Mesos lets organizations define their own allocation policies through a pluggable allocation module. For example, you might use fair sharing, priority-based allocation, or custom policies that reflect your organization's needs.
Resource Offers and Constraints
Mesos doesn't require frameworks to declare their needs upfront. Instead, frameworks can simply reject offers that don't meet their requirements and wait for better ones. However, this could be slow if a framework has specific needs.
To optimize this, Mesos supports filters: simple rules that tell Mesos what resources a framework will never accept. For example:
- "Only offer nodes from list L" (for data locality)
- "Only offer nodes with at least R resources free" (for large tasks)
Filters are just a performance optimization. Surprisingly, even without filters, the resource offer model works well for fine-grained tasks. A simple technique called delay scheduling—where frameworks wait 1-5 seconds for nodes with their data—achieves nearly optimal data locality.
Resource Allocation and Revocation
Mesos takes advantage of the fact that most tasks are short, reallocating resources as tasks finish. For example, if a framework deserves 10% of the cluster, it only needs to wait about 10% of the average task duration to receive its share (since that many resources become free in that time).
But what if some tasks run for a long time (due to a bug or a greedy framework)? Mesos can revoke (kill) tasks to free up resources:
- Before killing a task, Mesos gives the framework a grace period to clean up
- Frameworks can have a guaranteed allocation—resources they can hold without risk of revocation
- Tasks below the guaranteed allocation are never killed; tasks above it may be killed if needed
- Frameworks tell Mesos whether they want more resources through an API, helping Mesos decide when to trigger revocation
This is especially important for frameworks like MPI where killing tasks is very disruptive (since all tasks are interdependent).
Isolation
Mesos keeps frameworks from interfering with each other by leveraging existing OS isolation mechanisms (like Linux containers). Since these mechanisms vary by platform, Mesos supports multiple isolation approaches through pluggable modules.
Making Resource Offers Scalable and Robust
Several techniques keep the resource offer mechanism efficient:
-
Fast filter evaluation: Filters are simple Boolean checks (yes/no decisions) that can be evaluated quickly on the master without complex logic.
-
Accounting for offered resources: Mesos counts resources that have been offered to a framework toward that framework's allocation, even if the framework hasn't accepted them yet. This prevents frameworks from gaming the system by indefinitely holding onto offers.
-
Offer timeouts: If a framework doesn't respond to an offer within a reasonable time, Mesos rescinds the offer and makes those resources available to other frameworks.
Fault Tolerance
Mesos is designed to handle failures gracefully at multiple levels:
-
Master recovery: The master stores minimal "soft state"—just the list of active slaves, frameworks, and running tasks. This can be completely reconstructed if the master fails. Multiple masters run in hot-standby configuration using ZooKeeper for leader election, so if one fails, another takes over immediately.
-
Failure reporting: When nodes or executors crash, Mesos reports these failures to framework schedulers, which can then react according to their own policies (e.g., retry the task, fail the job, etc.).
-
Scheduler failover: Frameworks can register multiple schedulers. If one fails, Mesos notifies a backup scheduler to take over, ensuring continuous operation.
Mesos Behavior: When Does It Work Well?
The Ideal Scenario
Mesos performs very well when:
- Frameworks can scale elastically (up and down on demand)
- Task durations are similar/homogeneous
- Frameworks don't have strong preferences for specific nodes
Even when frameworks do prefer specific nodes, Mesos can match the performance of a centralized scheduler through its resource offer mechanism.
Elastic vs. Rigid Frameworks
There's an important distinction between two types of frameworks:
-
Elastic frameworks (like Hadoop and Dryad): Can start using resources immediately when offered and release them as soon as tasks finish. They can scale up and down dynamically.
-
Rigid frameworks (like MPI): Must acquire a fixed set of resources before starting and can't easily scale up or down. Killing a task in MPI is expensive because all tasks are tightly coordinated.
Elastic frameworks with consistent task durations work best with Mesos, while rigid frameworks with highly variable task durations are more challenging.
Resource Types
The paper distinguishes between:
- Mandatory resources: Resources a framework must have to run
- Preferred resources: Resources a framework would like (e.g., nodes with local data) but can work without
Performance Analysis
The authors analyze how well Mesos works compared to an omniscient centralized scheduler. They consider two scenarios:
(a) Enough preferred resources for everyone: If there's a configuration where every framework gets all its preferred resources, Mesos will converge to this optimal state within one average task duration. This is because as tasks finish and resources become available, frameworks can grab their preferred resources.
(b) Not enough preferred resources: When demand exceeds supply (e.g., multiple frameworks want the same machines for data locality), Mesos uses a lottery-style approach. It offers slots to frameworks with probabilities proportional to their fair share, achieving fair allocation even with competing preferences.
Handling Variable Task Durations
The paper considers both homogeneous (similar) and heterogeneous (variable) task durations:
-
The problem: In the worst case, a short job might need nodes that are all occupied by long-running tasks, forcing it to wait a long time relative to its execution time.
-
Why it works anyway: Random task assignment actually works well as long as most tasks aren't long-running and nodes can run multiple tasks simultaneously. Even with some long tasks, a framework with short tasks can still acquire many preferred slots quickly.
-
Additional optimization: Mesos can reserve some resources on each node specifically for short tasks, with a maximum duration limit. Tasks exceeding this limit get killed. This is similar to having a "short job queue" in HPC clusters, preventing long-running tasks from blocking quick jobs.
Framework Incentives
Like any decentralized system, it's important to understand what behaviors Mesos encourages. Mesos incentivizes frameworks to:
- Run short tasks: Resources become available more frequently, improving everyone's allocation
- Scale elastically: Accept resources when offered and release them promptly
- Be selective: Don't accept resources you can't use efficiently (this helps others get what they need)
Limitations of Distributed Scheduling
While powerful, the resource offer approach has some limitations:
-
Fragmentation: If resources are split across many nodes in small pieces, frameworks needing large allocations might struggle. Solution: Set a minimum offer size on each node, only making offers when enough resources are free.
-
Interdependent constraints: In rare cases with complex dependencies between frameworks (e.g., tasks from different frameworks that can't run on the same node), only a centralized scheduler might find the optimal allocation. In practice, this is uncommon.
-
Framework complexity: Resource offers might seem to add complexity to framework schedulers. However, this isn't really a burden because:
- Frameworks need to know their preferences regardless of whether they use Mesos
- Most framework schedulers are already online algorithms (adapting to failures and unpredictable task durations), which naturally fit the resource offer model
Implementation Details
Core Technology
- libprocess: A C++ library providing an actor-based programming model (where components communicate via messages) with efficient asynchronous I/O (using system-specific mechanisms like epoll on Linux and kqueue on BSD/Mac)
- ZooKeeper: Used for leader election among master nodes, ensuring high availability
Data Locality
To minimize network traffic, they use delay scheduling: frameworks wait a short time (1-5 seconds) for slots on nodes that already contain their input data, rather than immediately accepting any available slot. This simple technique achieves 90-95% data locality.
Framework Ports
- Hadoop port: Just 1,500 lines of code to make Hadoop work on Mesos
- Torque (used for MPI jobs): Because MPI jobs aren't fault-tolerant (you can't just restart one task), Torque only accepts resources up to its guaranteed allocation, avoiding the risk of task revocation
Spark Framework: A Case Study
To demonstrate Mesos's value, the authors built Spark, a specialized framework for a type of workload that performs poorly on Hadoop: iterative jobs where the same dataset is reused across many iterations. Machine learning algorithms like logistic regression are perfect examples.
Why Hadoop Struggles with Iterative Jobs
Take logistic regression as an example:
-
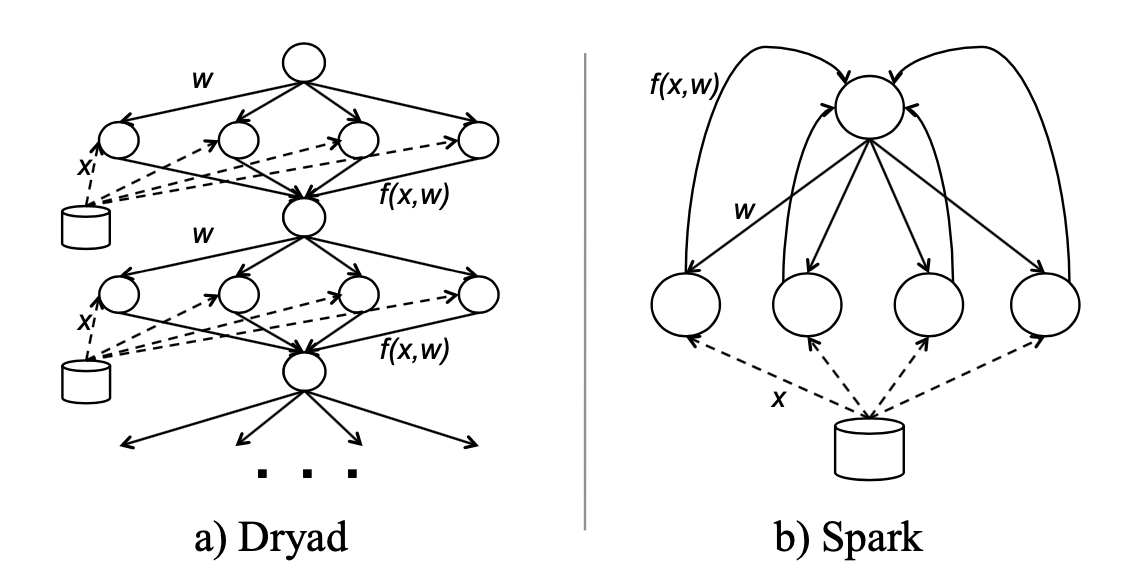
In Hadoop: Each iteration must run as a separate MapReduce job because each iteration depends on results from the previous one. Every iteration must re-read the entire input file from disk. This is extremely wasteful when you need 20-30 iterations.
-
In Dryad: You can express the whole job as one data flow graph (DAG), but the data still must be reloaded from disk at each iteration.
How Spark Solves This
Spark takes advantage of Mesos's long-lived executors to cache a slice of the dataset in memory at each executor. Multiple iterations can then run on this cached data without touching disk.
The caching is fault-tolerant: if a node crashes, Spark remembers how to recompute its data slice from the source. No data is permanently lost.
Results
- Code size: Just 1,300 lines of code (Mesos handled all the infrastructure)
- Performance: 10x faster than Hadoop for iterative jobs
- Development time: Saved by not having to write master/slave daemons and communication protocols—Mesos provided all this
The authors only needed to write:
- A framework scheduler (using delay scheduling for data locality)
- User-facing APIs for writing Spark programs
This demonstrates Mesos's core value proposition: making it easy to build specialized frameworks that outperform general-purpose solutions for specific workloads.
Evaluation: Does Mesos Actually Work?
The authors ran extensive experiments to validate Mesos's performance. Here are the key results:
Experiment Setup
- Comparison: Mesos (96-node cluster shared by 4 frameworks with fair sharing) vs. Static partitioning (each framework gets 24 dedicated nodes)
- Hardware: EC2 nodes with 4 CPU cores and 15 GB RAM
- Frameworks tested: Hadoop (large jobs), Hadoop (small jobs), Spark, and MPI
Key Results
-
Better Utilization and Performance
- Mesos achieves higher cluster utilization than static partitioning
- Jobs finish at least as fast, often faster, because they can use idle resources from other frameworks
- CPU utilization increases by 10%, memory by 17%
-
Dynamic Scaling Benefits
- Fine-grained frameworks (Hadoop and Spark) can scale beyond their 1/4 allocation when other frameworks are idle
- The large-job Hadoop mix benefits the most, performing 2x better on Mesos by filling gaps in other frameworks' demand
-
Minimal Overhead (under 4%)
- MPI job: 50.9s without Mesos → 51.8s with Mesos
- Hadoop job: 160s without Mesos → 166s with Mesos
- The overhead of using Mesos is negligible
-
Data Locality with Delay Scheduling
- Static partitioning: Only 18% data locality (terrible!)
- Mesos without delay scheduling: Already better (more nodes per framework)
- Mesos with 1-second delay: Over 90% locality
- Mesos with 5-second delay: 95% locality (as good as dedicated cluster)
- Result: Jobs run 1.7x faster with delay scheduling vs. static partitioning
-
Spark's 10x Speedup Confirmed
- Hadoop: 127s per iteration (each iteration is a separate job)
- Spark: First iteration 174s, subsequent iterations only 6s
- For 30 iterations: 10x faster than Hadoop
-
Scalability
- Tested with 50,000 emulated nodes
- Overhead to schedule a new framework remains under 1 second even at this scale
-
Fast Failure Recovery
- Mean time to recover from master failure: 4-8 seconds
- This includes detecting the failure and electing a new master
Related Work: How Does Mesos Compare?
HPC and Grid Schedulers
Traditional high-performance computing (HPC) and grid schedulers differ from Mesos in several ways:
- Designed for specialized hardware (supercomputers, scientific clusters)
- Use centralized scheduling
- Require users to declare resource requirements upfront at job submission
In contrast, Mesos:
- Works on commodity hardware
- Uses distributed scheduling (resource offers)
- Supports fine-grained sharing at the task level
- Lets frameworks dynamically control their own placement decisions
Cloud Computing (AWS, Azure, etc.)
Public and private clouds allocate resources at the virtual machine (VM) level, which is coarser-grained than Mesos:
- Clouds: Allocate whole VMs (e.g., "give me 10 VMs with 4 cores each")
- Mesos: Allocates at the task level (e.g., "run this specific task on these specific cores")
The VM model leads to:
- Less efficient resource utilization (unused capacity within VMs is wasted)
- Harder data sharing (each VM is isolated)
- Less precise task placement
Mesos allows frameworks to be highly selective about exactly where each task runs, optimizing for data locality and other constraints.
Conclusion
Mesos introduces resource offers, a distributed scheduling mechanism that elegantly solves the problem of sharing clusters among diverse frameworks. By delegating scheduling decisions to frameworks while Mesos handles fair allocation, the system achieves:
- Efficiency: High utilization through fine-grained sharing
- Flexibility: Support for diverse frameworks with different needs
- Simplicity: A thin layer that's easy to keep robust and scalable
- Performance: Near-zero overhead while enabling significant speedups
The paper demonstrates that you don't need a complex centralized scheduler to share clusters efficiently. Sometimes, the best solution is to divide responsibilities: let a simple system handle fair allocation while letting specialized frameworks handle their own complex scheduling logic.
Over the next few Saturdays, I'll be going through some of the foundational papers in Computer Science, and publishing my notes here. This is #16 in this series.