Spanner: Google’s Globally-Distributed Database
Abstract
Spanner is Google's scalable, multi-version, globally-distributed, and synchronously-replicated database. It is the first system to distribute data at global scale and support externally-consistent distributed transactions. This paper describes how Spanner is structured, its feature set, the rationale underlying various design decisions, and a novel time API that exposes clock uncertainty. This API and its implementation are critical to supporting external consistency and a variety of powerful features: non-blocking reads in the past, lock-free read-only transactions, and atomic schema changes, across all of Spanner.
What does this mean in simple terms? Spanner is a database that works across multiple data centers worldwide. Unlike traditional databases that struggle with consistency when spread across the globe, Spanner guarantees that all transactions happen in the correct order, even when servers are thousands of miles apart. The key innovation is a special time API called TrueTime that helps coordinate operations across this massive distributed system.
Introduction
The Big Picture: Spanner represents a major evolution in database design. While most databases are either globally distributed OR strongly consistent, Spanner achieves both. Here's what makes it special:
Architecture Overview:
- Spanner splits (shards) data across many sets of Paxos state machines in data centers around the world. Think of Paxos as a voting protocol that helps multiple servers agree on the correct state of data, even when some servers fail.
- Data is replicated across multiple locations for two key reasons: (1) so users anywhere in the world can access it quickly, and (2) so the system stays online even if entire data centers go down. When failures happen, clients automatically switch to working replicas without any downtime.
- The system automatically manages data distribution - resharding when data grows, migrating data between machines to balance load, and moving data between data centers when needed.
Design Scale: Spanner is designed to scale up to millions of machines across hundreds of data centers and trillions of database rows. Its first production customer was F1, a complete rewrite of Google's advertising backend.
Why Spanner Was Built: Google already had Bigtable, but users complained it was hard to use for applications with complex, evolving schemas or those needing strong consistency across geographic regions. Bigtable is essentially a key-value store, which is simple but limiting for many real-world applications.
Evolution: Spanner started as a Bigtable-like key-value store but evolved into something more powerful: a temporal multi-version database. Here's what that means:
- Schematized semi-relational tables: Unlike simple key-value stores, you can define structured tables with relationships between them (like in traditional SQL databases)
- Multi-version with timestamps: Every version of your data is automatically timestamped when it's committed, allowing you to query historical data
- Temporal queries: You can read data as it existed at any point in the past
- Garbage collection: Old versions are automatically cleaned up based on policies you configure
- SQL support: You can query data using familiar SQL instead of low-level key-value operations
- Full transactions: Support for ACID transactions across multiple rows and tables
Features
As a globally-distributed database, Spanner provides several interesting features that were previously thought impossible to achieve simultaneously:
1. Fine-Grained Replication Control
Applications have precise control over where their data lives and how it's replicated:
- Geographic placement: Specify exactly which data centers should contain which data (useful for data sovereignty and compliance)
- Latency optimization: Control how close data is to users (reduces read latency) and how far apart replicas are (affects write latency)
- Availability tuning: Choose how many replicas to maintain, balancing durability, availability, and read performance
2. External Consistency (The Hard Problem)
This is where Spanner really shines. Most distributed databases force you to choose between consistency and global distribution, but Spanner provides both:
- Externally consistent reads and writes: If a transaction T1 commits before another transaction T2 starts (in real wall-clock time), then T1's commit timestamp will be smaller than T2's. This might sound obvious, but it's extremely difficult to guarantee in a distributed system where clocks on different machines drift.
- Globally-consistent reads at a timestamp: You can query the entire database as it existed at any specific point in time, and get consistent results even though data is spread across the world.
What does "external consistency" mean? It's essentially linearizability for transactions - the system behaves as if all operations happen in a single, real-time order. If you commit a transaction and then tell your colleague about it, when they query the database, they're guaranteed to see your changes. This seems intuitive but is actually very hard to achieve in distributed systems.
3. TrueTime: The Secret Sauce
The key technology enabling these properties is TrueTime, a novel API that exposes clock uncertainty as a first-class concept. Here's how it works:
- Instead of pretending clocks are perfectly synchronized (they never are), TrueTime returns a time interval: "the current time is somewhere between X and Y"
- The uncertainty is kept remarkably small (generally less than 10ms) by using multiple modern clock references: GPS receivers and atomic clocks
- By explicitly accounting for clock uncertainty, Spanner can wait out the uncertainty interval when needed, guaranteeing that timestamps reflect the true order of events
Spanner was the first system to provide these guarantees at global scale, combining the impossible: worldwide distribution with strong consistency.
Implementation
Let's break down how Spanner is actually organized, from the highest level down to individual servers:
System Hierarchy:
A complete Spanner deployment is called a universe (Google has multiple universes for different purposes). Within a universe:
- Zones are the basic unit of deployment and physical isolation. Think of a zone as a group of servers that can fail independently. A data center might have multiple zones to isolate different applications or to separate testing from production.
- Each zone contains one zonemaster (which assigns data to servers) and between 100 to several thousand spanservers (which actually store data and serve client requests)
- Location proxies in each zone help clients find which spanservers have the data they need
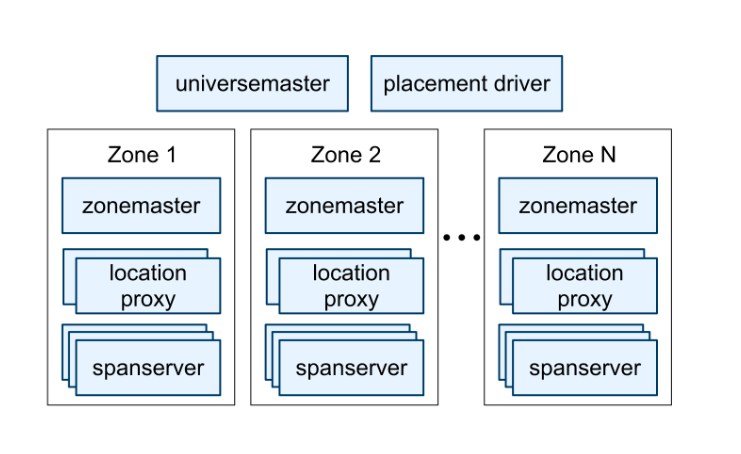
Coordinating Components:
Two global components coordinate the entire universe:
- Universe master: A monitoring console that displays status information for debugging. It doesn't serve client requests directly.
- Placement driver: The "traffic controller" that automatically moves data between zones every few minutes. It decides when to move data to meet your replication requirements or balance load across servers. Think of it as an automated database administrator that never sleeps.
Spanserver Software Stack
Now let's zoom in on what happens inside each individual spanserver. This is where the real magic happens:
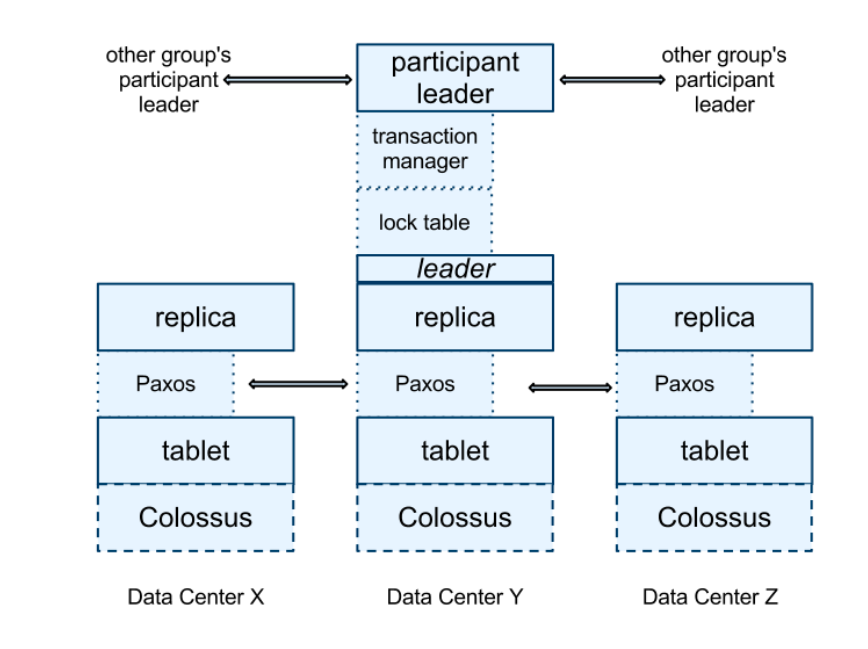
Storage Layer (Bottom):
Each spanserver manages between 100 and 1000 tablets - think of a tablet as a chunk of data similar to a partition in other databases. The key difference from Bigtable: every piece of data gets a timestamp, making this a true multi-version database rather than just a key-value store.
Tablets are stored using:
- B-tree-like files for the actual data (B-trees allow efficient lookups and range scans)
- Write-ahead log to ensure durability (changes are logged before being applied)
- Colossus: Google's distributed file system (successor to the famous Google File System), which handles the actual disk storage and replication
Consensus Layer (Middle):
This is where Paxos comes in. Each tablet is replicated across multiple servers using a Paxos group (a collection of replicas that vote to agree on changes):
- Writes must go through the Paxos leader, which coordinates the voting process to ensure all replicas agree
- Reads can go to any replica that's sufficiently up-to-date, making reads faster since you don't always need to contact the leader
- This design provides fault tolerance - if some replicas fail, the group can still make progress as long as a majority survives
Transaction Layer (Top):
At the leader replica, each spanserver runs additional components for managing transactions:
- Lock table: Implements two-phase locking for concurrency control. It tracks which ranges of keys are locked by which transactions, preventing conflicting operations from happening simultaneously.
- Transaction manager: Coordinates distributed transactions that span multiple Paxos groups. The leader acts as a "participant leader" (coordinating its local part of a distributed transaction), while other replicas are "participant slaves" that follow along.
This layered architecture allows Spanner to provide both local strong consistency (via Paxos) and global transactional consistency (via the transaction manager).
Directories and Placement
Spanner uses a concept called directories to organize data, which is key to understanding how the system manages billions of pieces of data efficiently:
What is a Directory?
A directory is the fundamental unit of data placement - think of it as a "bucket" of related data that moves together:
- All data in a directory shares the same replication configuration (same number of replicas, same geographic locations)
- When Spanner needs to move data between Paxos groups (for load balancing or to meet new placement requirements), it moves entire directories at once
- Applications can specify geographic placement policies at the directory level
Example: You might have a directory for each customer, so all of Customer A's data lives in a directory that's replicated in US data centers, while Customer B's data lives in a directory replicated in European data centers for GDPR compliance.
Handling Growth:
If a directory grows too large (say, a huge customer with terabytes of data), Spanner will automatically shard it into multiple fragments. These fragments can be served from different Paxos groups (and therefore different physical servers), allowing Spanner to scale beyond the capacity of any single machine while maintaining the logical concept of a directory.
Data Model
Spanner provides a hybrid data model that combines the best of both SQL databases and NoSQL key-value stores:
What You Get:
- Schematized semi-relational tables: Define tables with columns and types, similar to traditional SQL databases
- SQL query language: Write familiar SELECT, JOIN, and WHERE queries
- General-purpose transactions: Full ACID transactions that can span multiple rows and tables
Why This Design?
Google learned from earlier systems:
- Megastore showed that developers wanted structured tables with schemas and synchronous replication
- Bigtable lacked cross-row transactions, leading to constant complaints. Google built Percolator specifically to add transactions on top of Bigtable
- The Spanner team believed it's better to give developers full transactions and let them optimize for performance when needed, rather than forcing everyone to code around the lack of transactions
The clever part: running two-phase commit (the protocol for distributed transactions) over Paxos means transactions don't hurt availability the way they do in traditional databases. If a server fails mid-transaction, Paxos ensures the replicas can still complete it.
The Hybrid Nature:
Spanner isn't purely relational - it retains some key-value store DNA:
- Every table must have an ordered set of one or more primary-key columns
- These primary keys effectively become the "name" of a row, similar to keys in a key-value store
- Internally, each table is a mapping from primary-key columns to non-primary-key columns
This design allows Spanner to efficiently shard and route data (using the primary key) while still providing the familiar SQL interface developers expect.
TrueTime
TrueTime is perhaps the most innovative part of Spanner. It's a novel API that fundamentally changes how distributed systems think about time:

The Core Insight:
Traditional distributed systems pretend that time() returns an exact timestamp. But in reality, clocks on different machines are never perfectly synchronized - they drift apart over time. TrueTime takes a radically honest approach: it returns a time interval [earliest, latest] and guarantees that the actual current time is somewhere in that range.
The API:
TT.now()returns an interval, not a point in timeTT.after(t)returns true ifthas definitely passedTT.before(t)returns true ifthas definitely not arrived yet
How It Works:
The time epoch is based on UNIX time with leap-second smearing (spreading leap seconds across a longer period to avoid sudden jumps). But the real magic is in the time references:
TrueTime uses two types of clock hardware because they fail in completely different ways:
-
GPS receivers: Get time from GPS satellites
- Vulnerabilities: Antenna failures, local radio interference, GPS signal spoofing, incorrect leap-second handling, GPS system outages
-
Atomic clocks: Ultra-precise clocks based on atomic oscillations
- Vulnerabilities: Can drift over long periods due to frequency errors, but fail independently from GPS
By combining these two independent time sources, TrueTime can detect when one is wrong and maintain accuracy. If GPS fails, atomic clocks keep time accurate in the short term. If atomic clocks drift, GPS provides correction.
Why This Matters:
By exposing clock uncertainty explicitly, Spanner can make strong guarantees: if it says transaction A happened before transaction B, it's absolutely true, not just "probably true based on our clocks." The system can wait out the uncertainty interval when needed to ensure correctness.
Concurrency Control
Spanner supports three types of operations, each optimized for different use cases:
- Read-write transactions: Full ACID transactions that can modify data
- Read-only transactions: Predeclared snapshot-isolation transactions that don't modify data but need a consistent view
- Snapshot reads: Simple reads at a specific timestamp or at a bounded staleness interval
The paper dives deep into how TrueTime enables efficient implementation of these transaction types, including clever optimizations like:
- Non-blocking reads in the past (read historical data without locks)
- Lock-free read-only transactions (no locking overhead for queries)
- Atomic schema changes across the entire distributed database
This section is a masterclass in managing distributed reads and writes. If you're interested in the low-level details of how distributed transactions work, I highly recommend reading the full section in the original paper.
Other Interesting Stuff
Clock Reliability Myth-Busting:
One concern about TrueTime might be: "What if the clocks break?" Google's machine statistics provide a surprising answer: bad CPUs are 6 times more likely than bad clocks. Clock issues are extremely rare compared to other hardware failures. This data suggests TrueTime's implementation is as trustworthy as any other critical software component.
F1: The First Production Customer
Spanner's first real-world test came in early 2011 when Google rewrote its advertising backend (called F1) to use it. This was a bold move - replacing a critical revenue-generating system with a brand-new database technology.
The context:
- F1's dataset was tens of terabytes (small by NoSQL standards, but large enough to cause problems)
- The existing system used sharded MySQL, which was becoming painful to manage
- The application needed strong transactional guarantees that NoSQL databases couldn't provide
Why F1 chose Spanner:
-
No manual resharding: Spanner automatically handles data distribution as it grows. With sharded MySQL, engineers had to manually split data across shards and rebalance when things got uneven - a time-consuming and error-prone process.
-
Synchronous replication with automatic failover: If a data center goes down, Spanner automatically routes traffic to healthy replicas without data loss. This is crucial for an advertising system that can't afford downtime.
-
Strong transactional semantics: F1 needed ACID transactions across multiple rows and tables. Most NoSQL systems at the time offered eventual consistency at best, which wasn't sufficient for financial data.
F1's success proved that Spanner could handle demanding production workloads while delivering on its promises of global consistency and high availability.
Conclusions
Spanner represents a landmark achievement in database systems by bridging two traditionally separate worlds:
From the database community:
- Familiar, easy-to-use semi-relational tables and schemas
- Full ACID transactions across multiple rows and tables
- SQL-based query language that developers already know
From the distributed systems community:
- Massive scalability (millions of machines, trillions of rows)
- Automatic sharding and data placement
- Fault tolerance through replication
- Wide-area distribution across continents
- External consistency (linearizability) at global scale
The conventional wisdom before Spanner was that you had to choose: either have a consistent database (like traditional SQL databases) or have global distribution (like NoSQL systems). Spanner proved this was a false dichotomy.
The Key Insight: By explicitly modeling clock uncertainty through TrueTime and combining multiple independent time sources (GPS and atomic clocks), Spanner could provide strong consistency guarantees even across geographically distributed data centers.
This paper showed that with the right abstractions and sufficient engineering effort, you can build a database that doesn't force you to choose between consistency and availability - you can have both.
Over the next few Saturdays, I'll be going through some of the foundational papers in Computer Science, and publishing my notes here. This is #10 in this series.