Out of the Tar Pit
What is this paper about?
"Out of the Tar Pit" is a highly influential 2006 paper that tackles the biggest challenge in software development: complexity. The authors argue that complexity is the root cause of most problems in large software systems—making them hard to understand, maintain, and debug.
The paper builds on Fred Brooks's classic essay "No Silver Bullet," which distinguished between:
- Essential complexity: The inherent difficulty of the problem you're solving (what your users actually need)
- Accidental complexity: Extra difficulty created by our tools, languages, and implementation choices
However, Moseley and Marks disagree with Brooks's conclusion. While Brooks believed most remaining complexity is essential, they argue that most complexity in modern systems is actually accidental and can be eliminated. They propose a solution called Functional Relational Programming (FRP) that combines functional programming with relational databases to minimize this accidental complexity.
"Complexity is the single major difficulty in the successful development of large-scale software systems. Following Brooks we distinguish accidental from essential difficulty, but disagree with his premise that most complexity remaining in contemporary systems is essential."
The Core Philosophy
The paper takes a refreshing approach: rather than just providing tools to cope with complexity, it focuses on preventing complexity in the first place. This is a crucial distinction—instead of better debugging tools or testing frameworks, the authors ask "how can we avoid creating the mess to begin with?"
When we try to understand how a system works, we typically use two approaches:
- Testing: Running the program with various inputs to see what happens
- Informal Reasoning: Mentally simulating how the code will behave, thinking through the logic
Both approaches struggle when systems become complex. The authors argue that we need to design systems that are fundamentally simpler to test and reason about.
"Our response to mistakes should be to look for ways that we can avoid making them, not to blame the nature of things."
The Three Main Causes of Complexity
1. State: The Biggest Villain
State refers to any data that can change over time—variables, database records, file contents, etc. The authors identify state as the single biggest cause of complexity in modern systems.
Why is state so problematic?
Impact on Testing: Imagine you're testing a function. If your program has state, you need to consider not just the inputs to that function, but also what state the system is currently in. Did the user just log in? Is the shopping cart empty or full? The number of possible states is often even larger than the number of possible inputs, creating a combinatorial explosion of test scenarios.
Impact on Understanding Code: When you read a stateless function, you can understand it in isolation—same inputs always produce same outputs. But with state, you need to mentally track "what might the system look like when this code runs?" This mental burden grows rapidly as state increases.
The Exponential Problem: Every single bit of state you add doubles the total number of possible states in your system. Add 10 boolean flags, and you've created 1,024 possible state combinations.
State Contamination: Even if a function doesn't directly use state, if it calls another function that does use state (even indirectly), the complexity spreads like a virus. Suddenly, you can't understand the first function without understanding the entire state of the system.
The authors believe that most state in typical systems simply isn't necessary—it's accidental complexity that could be eliminated with better design.
2. Control Flow: The Problem of "How" vs "What"
Control flow refers to the order in which individual statements, instructions, or function calls are executed. The problem arises when languages force you to specify the detailed steps of how to accomplish something, rather than just declaring what you want.
For example, instead of saying "give me all users older than 18," you might have to write: "create a loop, iterate through each user, check if their age is greater than 18, if yes add them to a result list, continue until end." This over-specification adds complexity.
There's also the challenge of concurrency: when multiple things happen simultaneously, the order of operations becomes unpredictable, making testing nearly impossible since the same test might produce different results on different runs.
3. Other Contributors to Complexity
While state and control are the primary culprits, there are other sources:
- Code Volume: More code simply means more to understand and maintain
- Duplicated Code: The same logic repeated in multiple places
- Dead Code: Code that's never executed but still needs to be understood
- Missed or Unnecessary Abstractions: Either too much abstraction (making things obscure) or too little (making things repetitive)
- Poor Modularity: When parts of the system are tightly coupled rather than independent
Important Principles:
- Complexity Breeds Complexity: One compromise or shortcut early on can cascade into disaster later
- Simplicity Is Hard: It requires discipline and upfront effort
- Power Corrupts: The more powerful and flexible a programming language, the harder it is to understand systems built in it. Languages with restrictions and guarantees (like strong type systems) actually make code easier to understand
How Different Programming Paradigms Handle Complexity
Before proposing their solution, the authors analyze how existing programming approaches deal with complexity.
Object-Oriented Programming (OOP)
The verdict is harsh: traditional OOP suffers from both state and control complexity. Objects encapsulate mutable state, and the typical imperative style forces explicit control flow. While OOP can help organize code, it doesn't fundamentally solve the complexity problem.
Functional Programming
Functional programming offers significant advantages by avoiding mutable state. In functional languages, once you create a value, it never changes—you create new values instead of modifying old ones.
Key benefits:
- Referential Transparency: The same function called with the same arguments always returns the same result, no hidden state to worry about
- Easier Testing and Reasoning: Functions can be understood in isolation
- You can adopt functional style even in imperative languages: It's a discipline, not just a language feature
The Trade-off: Writing purely functional code requires more upfront thought (you can't take the "shortcut" of just mutating variables), but this one-time cost pays off continuously since the code is read, tested, and debugged far more often than it's written.
Interestingly, instead of mutating state, functional programs often pass additional parameters between functions to track what would otherwise be mutable state—a cleaner approach that makes data flow explicit.
Logic Programming
Logic programming (like Prolog) takes a declarative approach: you state what the problem is and what constitutes a solution, rather than how to compute it. You write axioms (logical rules) that describe the problem, and the system figures out how to find solutions.
This paradigm shares with functional programming an emphasis on "what not how," which naturally reduces control-flow complexity.
Essential vs. Accidental Complexity: A Deeper Look
This distinction is central to the paper's argument:
Essential Complexity is the complexity inherent to the problem your users are trying to solve. If you're building an e-commerce site, you need to handle products, orders, payments, shipping—that's the essence of the problem. You can't eliminate this complexity; it's what your software is supposed to do.
Accidental Complexity is everything else—complexity created by our implementation choices, programming languages, frameworks, performance optimizations, and infrastructure. In an ideal world with perfect tools, we wouldn't need to deal with any of this.
The Authors' Key Insight: The vast majority of state in typical systems is accidental, not essential. Most of the complexity we struggle with is self-inflicted and could be eliminated with better approaches.
When Is Accidental Complexity Justified?
Even in an ideal world, there are two valid reasons to accept some accidental complexity:
- Performance: Sometimes you need to cache data, use mutable structures, or add explicit control flow to meet performance requirements
- Ease of Expression: Sometimes the most direct way to express something requires a bit of accidental complexity
The Path Forward: Avoid and Separate
The authors propose two guiding principles that should be the top priority in system design:
- Avoid: Eliminate accidental complexity wherever possible
- Separate: When you can't avoid complexity, isolate it from the essential parts
The key innovation they propose is separating the system into three distinct components, each with its own restricted language:
- Essential state
- Essential logic
- Accidental state and control (performance optimizations)
Using restricted languages for each component prevents complexity from spreading. Remember: complexity breeds complexity—one early compromise can cascade into long-term disaster. These principles must be overriding considerations, not afterthoughts.
Why the Relational Model?
When most people hear "relational model," they think "databases" (SQL, PostgreSQL, etc.). But the authors make a crucial point: the relational model isn't just for databases—it's a general approach to structuring and managing data that can be applied anywhere.
Think of the relational model (invented by Edgar F. Codd) as a mathematical framework for organizing information into tables (relations) with rows and columns. It provides:
- Structure: Representing all data as relations (tables)
- Manipulation: A declarative way to query and derive new data (like SQL queries—you say "what" you want, not "how" to get it)
- Integrity: Rules to ensure data stays consistent (like "every order must have a valid customer")
- Data Independence: A clear separation between the logical view of data (what it represents) and physical storage (how it's stored on disk)
Why is this relevant for fighting complexity? The relational model naturally embodies the "what not how" philosophy. When you write a SQL query, you don't specify loops, conditionals, or the order of operations—you just describe the data you want. The system figures out how to get it. This eliminates control-flow complexity.
Additionally, the relational model provides a disciplined way to organize state with clear integrity rules, preventing much of the chaos that comes from ad-hoc state management.
The Proposed Solution: Functional Relational Programming (FRP)
Now we arrive at the authors' proposed solution. Functional Relational Programming (FRP) combines the best of functional programming (no mutable state, pure functions) with the relational model (structured data, declarative queries).
How FRP Works
In FRP, you split your system into four separate components:
1. Essential State All the truly necessary state is stored as relations (tables). This is the minimum state your users' problems require—customer records, product inventory, order history, etc. Critically, this state is immutable in the sense that you never update records in place; instead, you specify transformations that produce new versions.
2. Essential Logic The business logic is expressed using relational algebra (think SQL-like queries) extended with pure functions. For example: "derived_relation: premium_customers = customers WHERE total_purchases > 1000." You're declaring relationships between data, not writing procedural code with loops and conditionals. Pure functions mean no side effects—same inputs always produce same outputs.
3. Accidental State and Control This is where you put performance optimizations that aren't conceptually necessary but practically needed—caches, indexes, specific algorithms for efficiency. By isolating this in its own component with a declarative specification, you prevent performance concerns from contaminating your essential logic.
4. Other (Interfaces) Specifications for how the system interacts with the outside world—user interfaces, APIs, external systems. This keeps I/O concerns separate from core logic.
Why This Architecture Reduces Complexity
- Separation of Concerns: Each component has a clear, limited responsibility
- Restricted Languages: Each component uses a language that restricts what you can do, preventing accidental complexity from creeping in
- Declarative Style: You say "what" not "how," eliminating control-flow complexity
- Controlled State: State is explicit, structured, and isolated to the essential state component
Key Takeaways
The paper's message is clear: complexity is the enemy, and simplicity is the way out.
The authors' recommendations, in order of priority:
- Avoid state whenever possible—the less state, the simpler the system
- Avoid explicit control flow where you can—use declarative approaches that specify "what" not "how"
- Eliminate unnecessary code—every line of code is a liability
When you must deal with complexity, separate it clearly from the essential parts of your system. The three-part separation (essential state, essential logic, accidental optimizations) provides a template for this.
Is FRP the silver bullet? The authors are modest—maybe, maybe not. But they're certain about one thing: simplicity itself is the answer. Not a framework, not a tool, not a methodology—but the relentless, disciplined pursuit of simplicity.
The "tar pit" in the title refers to the La Brea Tar Pits in Los Angeles, where prehistoric animals became trapped and couldn't escape. Similarly, complexity in software can trap projects, making them impossible to maintain or extend. The only way out is to design for simplicity from the start.
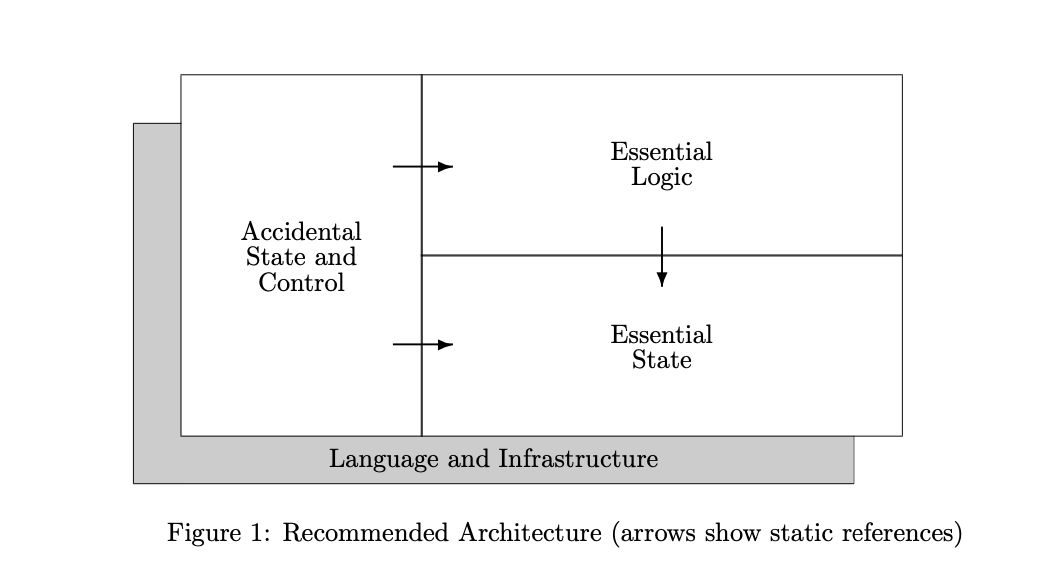
The diagram above shows the FRP architecture with clear separation between essential state, essential logic, and accidental concerns.
Further Reading
Want to dive deeper? Here are the resources:
- Original Paper (PDF) - The full text by Moseley and Marks
- Annotated Copy - With my notes and highlights
Related Papers to Explore:
- "No Silver Bullet" by Fred Brooks - The 1986 essay that started the essential vs. accidental complexity discussion
- Edgar F. Codd's original papers on the relational model - The foundation for half of FRP
This is part of my series reading foundational Computer Science papers. Check out more paper reviews from the series.